LLM . int8(): 8-bit Matrix Multiplication for Transformers at Scale
Abstract
Large language models have been widely adopted but require significant GPU memory for inference. We develop a procedure for Int8 matrix multiplication for feed-forward and attention projection layers in transformers, which cut the memory needed for inference by half while retaining full precision performance. With our method, a 175B parameter 16/32-bit checkpoint can be loaded, converted to Int8, and used immediately without performance degradation. This is made possible by understanding and working around properties of highly systematic emergent features in transformer language models that dominate attention and transformer predictive performance. To cope with these features, we develop a two-part quantization procedure, LLM.int8(). We first use vector-wise quantization with separate normalization constants for each inner product in the matrix multiplication, to quantize most of the features. However, for the emergent outliers, we also include a new mixed-precision decomposition scheme, which isolates the outlier feature dimensions into a 16-bit matrix multiplication while still more than $99.9 %$ of values are multiplied in 8-bit. Using LLM.int8(), we show empirically it is possible to perform inference in LLMs with up to 175B parameters without any performance degradation. This result makes such models much more accessible, for example making it possible to use OPT-175B/BLOOM on a single server with consumer GPUs. We open source our software.
大型语言模型已被广泛采用,但需要大量 GPU 内存进行推理。我们为 Transformer 中的前馈层和注意力投射层开发了一个 Int8 矩阵乘法程序,该程序将推理所需的内存减少了一半,同时保持了完整的精度性能。使用我们的方法,可以加载 175B 参数 16/32 bit 权重参数,将其转换为 Int8,并立即使用而不会降低性能。通过理解和解决 transformer 语言模型中主导注意力和 transformer 预测性能的高度系统化涌现特征的特性,这成为可能。为了应对这些特征,我们开发了一个由两部分组成的量化程序,LLM.int8()。我们首先对矩阵乘法中的每个内积使用具有单独归一化常数的向量量化,以量化大部分特征。然而,对于出现的异常值,我们还包括一个新的混合精度分解方案,它将异常值特征维度隔离为 16 Bit矩阵乘法,同时仍然超过99.9%的值以 8 Bit相乘。使用 LLM.int8(),我们凭经验证明可以在具有多达 175B 个参数的 LLM 中执行推理而不会降低任何性能。这一结果使此类模型更易于访问,例如,可以在具有消费类 GPU 的单个服务器上使用 OPT-175B/BLOOM。我们开源了我们的软件。
Introduction
Large pretrained language models are widely adopted in NLP (Vaswani et al., 2017; Radford et al., 2019; Brown et al., 2020; Zhang et al., 2022) but require significant memory for inference. For large transformer language models at and beyond 6.7B parameters, the feed-forward and attention projection layers and their matrix multiplication operations are responsible for $95 % %^{2}$ of consumed parameters and 65-85% of all computation (Ilharco et al., 2020). One way to reduce the size of the parameters is to quantize them to less bits and use low-bit-precision matrix multiplication. With this goal in mind, 8-bit quantization methods for transformers have been developed (Chen et al., 2020; Lin et al., 2020; Zafrir et al., 2019; Shen et al., 2020). While these methods reduce memory use, they degrade performance, usually require tuning quantization further after training, and have only been studied for models with less than 350M parameters. Degradation-free quantization up to $350 \mathrm{M}$ parameters is poorly understood, and multi-billion parameter quantization remains an open challenge.
介绍
大型预训练语言模型在 NLP 中得到广泛采用(Vaswani 等人,2017 年;Radford 等人,2019 年;Brown 等人,2020 年;Zhang 等人,2022 年),但需要大量内存才能进行推理。对于 6.7B 参数及以上的大型 transformer 语言模型,前馈和注意力投影层及其矩阵乘法运算占用了95%的参数(其他参数主要来自嵌入层。一小部分来自norms和bias。)和所有计算的 65-85%(Ilharco 等人,2020)。减小参数大小的一种方法是将它们量化为更少的 Bit 并使用低Bit 精度矩阵乘法。考虑到这一目标,目前已经开发了用于Transformer的 8 Bit量化方法(Chen 等人,2020 年;Lin 等人,2020 年;Zafrir 等人,2019 年;Shen 等人,2020 年)。虽然这些方法减少了内存使用,但它们降低了性能,通常需要在训练后进一步调整量化,并且只针对参数少于 350M 的模型进行了研究。对于参数量高达 350M 的无退化量化知之甚少,数十亿参数量化仍然是一个开放的挑战。
In this paper, we present the first multi-billion-scale Int8 quantization procedure for transformers that does not incur any performance degradation. Our procedure makes it possible to load a 175B parameter transformer with 16 or 32-bit weights, convert the feed-forward and attention projection layers to 8-bit, and use the resulting model immediately for inference without any performance degradation. We achieve this result by solving two key challenges: the need for higher quantization precision at scales beyond 1B parameters and the need to explicitly represent the sparse but systematic large magnitude outlier features that ruin quantization precision once they emerge in all transformer layers starting at scales of 6.7B parameters. This loss of precision is reflected in C4 evaluation perplexity (Section 3) as well as zeroshot accuracy as soon as these outlier features emerge, as shown in Figure 1.
在本文中,我们提出了第一个不会导致数十亿规模 Transformer 任何性能下降的 Int8 量化程序。我们的程序可以加载具有 16 Bit 或 32 Bit权重的 175B 参数的 Transformer,将前馈和注意力投影层转换为 8 Bit,并立即使用得到的模型进行推理,而不会降低性能。我们通过解决两个关键挑战来实现这一结果:
- 在超过 1B 参数的尺度上需要更高的量化精度
- 需要显式表示稀疏但系统的大量异常值特征,一旦它们出现在所有 transformer 层中,这些特征就会破坏量化精度。这一现象出现在 6.7B 参数规模。一旦出现这些异常值特征,这种精度损失就反映在 C4 评估困惑度(第 3 节)以及 zeroshot 精度上,如图 1 所示。
We show that with the first part of our method, vector-wise quantization, it is possible to retain performance at scales up to 2.7B parameters. For vector-wise quantization, matrix multiplication can be seen as a sequence of independent inner products of row and column vectors. As such, we can use a separate quantization normalization constant for each inner product to improve quantization precision. We can recover the output of the matrix multiplication by denormalizing by the outer product of column and row normalization constants before we perform the next operation.
我们表明,使用我们方法的第一部分,即向量量化,可以在高达 2.7B 参数的尺度上保持性能。对于向量层的量化,矩阵乘法可以看作是行向量和列向量的独立内积序列。因此,我们可以为每个内积使用单独的量化归一化常数来提高量化精度。在执行下一个操作之前,我们可以通过对列和行归一化常数的外积进行反归一化来恢复矩阵乘法的输出。
To scale beyond 6.7B parameters without performance degradation, it is critical to understand the emergence of extreme outliers in the feature dimensions of the hidden states during inference. To this end, we provide a new descriptive analysis which shows that large features with magnitudes up to $20 \mathrm{x}$ larger than in other dimensions first appear in about $25 %$ of all transformer layers and then gradually spread to other layers as we scale transformers to $6 \mathrm{~B}$ parameters. At around 6.7B parameters, a phase shift occurs, and all transformer layers and $75 %$ of all sequence dimensions are affected by extreme magnitude features. These outliers are highly systematic: at the 6.7B scale, 150,000 outliers occur per sequence, but they are concentrated in only 6 feature dimensions across the entire transformer. Setting these outlier feature dimensions to zero decreases top-1 attention softmax probability mass by more than $20 %$ and degrades validation perplexity by $600-1000 %$ despite them only making up about $0.1 %$ of all input features. In contrast, removing the same amount of random features decreases the probability by a maximum of $0.3 %$ and degrades perplexity by about $0.1 %$.
为了在不降低性能的情况下扩展超过 6.7B 参数,了解推理过程中隐藏状态的特征维度中极端异常值的出现至关重要。为此,我们提供了一种新的描述性分析,表明具有比其他维度高20倍大小的大型特征首先出现在约25%的所有Transformer层中,并随着转换器扩展到6B个参数而逐渐传播到其他层。在大约6.7B个参数时,发生了相变,所有Transformer层和75%的序列维度都受到极端幅度特征的影响。这些异常值是高度系统化的:在规模为6.7B时,每个序列会出现150,000个异常值,但它们仅集中在整个转换器中的6个特征维度中。研究人员发现,将这些异常特征维度设置为零会使top-1注意力softmax概率质量降低超过20%,并且使验证困惑度下降600-1000%,尽管它们仅占所有输入特征的约0.1%。相比之下,删除相同数量的随机特征最多只会使概率下降0.3%,困惑度仅下降约0.1%。
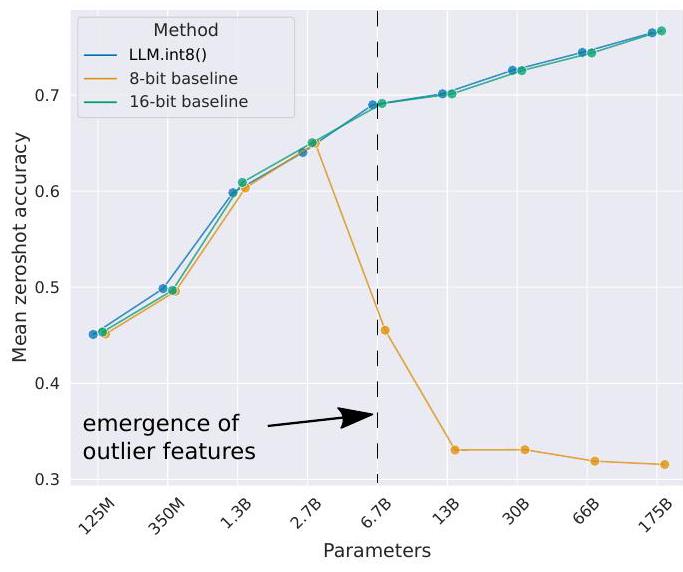
Figure 1: OPT model mean zeroshot accuracy for WinoGrande, HellaSwag, PIQA, and LAMBADA datasets. Shown is the 16-bit baseline, the most precise previous 8-bit quantization method as a baseline, and our new 8-bit quantization method, LLM.int8(). We can see once systematic outliers occur at a scale of 6.7B parameters, regular quantization methods fail, while LLM.int8() maintains 16-bit accuracy.
图 1:OPT 模型平均 WinoGrande、HellaSwag、PIQA 和 LAMBADA 数据集的零样本准确度。显示的是16位基线,最精确的前8位量化方法作为基线,我们的新8位量化方法LLM.int8()。我们可以看到,一旦系统异常值出现在 6.7B 参数的范围内,常规量化方法就会失败,而 LLM.int8() 保持 16 位的准确度.
To support effective quantization with such extreme outliers, we develop mixed-precision decomposition, the second part of our method. We perform 16-bit matrix multiplication for the outlier feature dimensions and 8-bit matrix multiplication for the other $99.9 %$ of the dimensions. We name the combination of vector-wise quantization and mixed precision decomposition, LLM.int8(). We show that by using LLM.int8(), we can perform inference in LLMs with up to 175B parameters without any performance degradation. Our method not only provides new insights into the effects of these outliers on model performance but also makes it possible for the first time to use very large models, for example, OPT-175B/BLOOM, on a single server with consumer GPUs. While our work focuses on making large language models accessible without degradation, we also show in Appendix D that we maintain end-to-end inference runtime performance for large models, such as BLOOM-176B and provide modest matrix multiplication speedups for GPT-3 models of size 6.7B parameters or larger. We open-source our software ${ }^{3}$ and release a Hugging Face Transformers (Wolf et al., 2019) integration making our method available to all hosted Hugging Face Models that have linear layers.
为了支持这种极端离群值的有效量化,我们开发了混合精度分解,这是我们方法的第二部分。对于离群特征维度,我们执行16 Bit矩阵乘法;对于其他99.9%的维度,我们执行8Bit矩阵乘法。我们将向量量化和混合精度分解相结合,并命名为LLM.int8()。通过使用LLM.int8(),我们可以在具有高达175B参数的LLMs中进行推断而不会出现任何性能下降。我们的方法不仅提供了关于这些离群值对模型性能影响的新见解,还使首次可以在单个具有消费者GPU的服务器上使用非常大的模型,例如OPT-175B/BLOOM。 虽然我们的工作重点是使大型语言模型无损可用,但附录D中也显示出,在保持端到端推理运行时性能方面表现良好(如BLOOM-176B),并且为GPT-3大小为6.7B参数或更大的模型提供适当程度地矩阵乘法加速。 我们开源软件并发布Hugging Face Transformers (Wolf et al., 2019)集成程序,使我们的方法可用于所有具有线性层的托管Hugging Face模型。

Figure 2: Schematic of LLM.int8(). Given 16-bit floating-point inputs $\mathbf{X}{f 16}$ and weights $\mathbf{W}$, the features and weights are decomposed into sub-matrices of large magnitude features and other values. The outlier feature matrices are multiplied in 16-bit. All other values are multiplied in 8-bit. We perform 8-bit vector-wise multiplication by scaling by row and column-wise absolute maximum of $\mathbf{C}{x}$ and $\mathbf{C}$ and then quantizing the outputs to Int8. The Int 32 matrix multiplication outputs $\mathbf{O u t}{i 32}$ are dequantization by the outer product of the normalization constants $\mathbf{C} \otimes \mathbf{C}_{w}$. Finally, both outlier and regular outputs are accumulated in 16-bit floating point outputs.
图2:LLM.int8()示意图。给定 16 位浮点输入 Xf 16 和权重 Wf 16,特征和权重被分解为大幅度特征和其他值的子矩阵。异常值特征矩阵乘以 16 位。所有其他值乘以 8 位。我们通过按 Cx 和 Cw 的行和列绝对最大值缩放来执行 8 位向量乘法,然后将输出量化为 Int8。 Int32 矩阵乘法输出 Outi32 由归一化常数 Cx ⊗ Cw 的外积去量化。最后,异常值和常规输出都累积在 16 位浮点输出中。
Background
In this work, push quantization techniques to their breaking point by scaling transformer models. We are interested in two questions: at which scale and why do quantization techniques fail and how does this related to quantization precision? To answer these questions we study high-precision asymmetric quantization (zeropoint quantization) and symmetric quantization (absolute maximum quantization). While zeropoint quantization offers high precision by using the full bit-range of the datatype, it is rarely used due to practical constraints. Absolute maximum quantization is the most commonly used technique.
当我们将 Transformer 模型扩展到更大规模时,我们对量化技术进行了深入研究,以探索其极限。我们感兴趣的问题有两个:量化技术在哪个规模上以及为什么会失败,以及这与量化精度有何关系?为了回答这些问题,我们研究了高精度的非对称量化(零点量化)和对称量化(绝对最大量化)两种技术。虽然使用整个数据类型的比特范围可以实现高精度的零点量化,但由于实际限制,它很少被使用。相比之下,绝对最大量化是最常用的一种技术。
8-bit Data Types and Quantization
Absmax quantization scales inputs into the 8-bit range $[-127,127]$ by multiplying with $s_{x_{f 16} }$ which is 127 divided by the absolute maximum of the entire tensor. This is equivalent to dividing by the infinity norm and multiplying by 127 . As such, for an FP16 input matrix $\mathbf{X}_{f 16} \in \mathbb{R}^{s \times h}$ Int8 absmax quantization is given by:
- Absmax量化
绝对最大量化将输入通过乘以 sxf16(即 127 除以整个张量的绝对最大值)缩放到 8 Bit范围 [-127, 127] 内。这等价于除以无穷范数并乘以 127。因此,对于 FP16 输入矩阵 Xf16 ∈ R^s×h,Int8 绝对最大量化的计算方式为: $$ \mathbf{X}{i 8}=\left\lfloor\frac{127 \cdot \mathbf{X} }{\max {i j}\left(\mid \mathbf{X}{\left.f 16_{i j} \mid\right)}\right.}\right\rceil=\left\lfloor\frac{127}{\left|\mathbf{X}{f 16}\right|{\infty} } \mathbf{X}{f 16}\right\rceil=\left\lfloor s } \mathbf{X}_{f 16}\right\rceil, $$
where \lfloor\rceil indicates rounding to the nearest integer.
Zeropoint quantization shifts the input distribution into the full range $[-127,127]$ by scaling with the normalized dynamic range $n d_{x}$ and then shifting by the zeropoint $z p_{x}$. With this affine transformation, any input tensors will use all bits of the data type, thus reducing the quantization error for asymmetric distributions. For example, for ReLU outputs, in absmax quantization all values in $[-127,0)$ go unused, whereas in zeropoint quantization the full $[-127,127]$ range is used. Zeropoint quantization is given by the following equations:
- 零点量化
通过使用归一化动态范围ndx进行缩放,然后通过零点zpx进行移位,将输入分布转换为完整范围[−127, 127]。通过这种仿射变换,任何输入张量都将使用数据类型的所有Bit,从而减少了不对称分布的量化误差。例如,在ReLU输出中,在absmax量化中[−127,0)内的所有值都未被使用,而在零点量化中则使用了完整的[−127, 127] 范围。 零点量化由以下方程给出: $$ \begin{gathered} n d_{x_{f 16} }=\frac{2 \cdot 127}{\max {i j}\left(\mathbf{X}^{i j}\right)-\min {i j}\left(\mathbf{X}^{i j}\right)} \ z p_{x_{i 16} }=\left\lfloor\mathbf{X}{f 16} \cdot \min {i j}\left(\mathbf{X}^{i j}\right)\right\rceil \ \mathbf{X}=\left\lfloor n d_{x_{f 16} } \mathbf{X}_{f 16}\right\rceil \end{gathered} $$
To use zeropoint quantization in an operation we feed both the tensor $\mathbf{X}{i 8}$ and the zeropoint $z p }$ into a special instruction ${ }^{4}$ which adds $z p_{x_{i 16} }$ to each element of $\mathbf{X}{i 8}$ before performing a 16-bit integer operation. For example, to multiply two zeropoint quantized numbers $A$ and $B_{i 8}$ along with their zeropoints $z p_{a_{i 16} }$ and $z p_{b_{i 16} }$ we calculate:
为了在操作中使用零点量化,我们将张量xi8和零点zpxi16输入到一个特殊的指令4中,在执行16位整数操作之前,将zpxi16添加到xi8的每个元素。例如,为了将两个零点量化数字 Ai8 和 Bi8 及其零点 zpai16 和 zpbi16 相乘,我们计算: $$ C_{i 32}=\operatorname{multiply}{i 16}\left(A } }, B_{z p_{b_{i 16} } }\right)=\left(A_{i 8}+z p_{a_{i 16} }\right)\left(B_{i 8}+z p_{b_{i 16} }\right) $$
where unrolling is required if the instruction multiply ${ }_{i 16}$ is not available such as on GPUs or TPUs:
$$ C_{i 32}=A_{i 8} B_{i 8}+A_{i 8} z p_{b_{i 16} }+B_{i 8} z p_{a_{i 16} }+z p_{a_{i 16} } z p_{b_{i 16} }, $$
where $A_{i 8} B_{i 8}$ is computed with Int8 precision while the rest is computed in Int16/32 precision. As such, zeropoint quantization can be slow if the multiply ${ }{i 16}$ instruction is not available. In both cases, the outputs are accumulated as a 32-bit integer $C$. To dequantize $C_{i 32}$, we divide by the scaling constants $n d_{a_{f 16} }$ and $n d_{b_{f 16} }$.
Int8 Matrix Multiplication with 16-bit Float Inputs and Outputs. Given hidden states $\mathbf{X}{f 16} \in \mathbb{R}^{s \times h}$ and weights $\mathbf{W} \in \mathbb{R}^{h \times o}$ with sequence dimension $s$, feature dimension $h$, and output dimension $o$ we perform 8-bit matrix multiplication with 16-bit inputs and outputs as follows:
$$ \begin{aligned} \mathbf{X}{f 16} \mathbf{W}=\mathbf{C}{f 16} & \approx \frac{1}{c } c_{w_{f 16} } } \mathbf{C}{i 32}=S \cdot \mathbf{C}{i 32} \ & \approx S \cdot \mathbf{A}{i 8} \mathbf{B}=S_{f 16} \cdot Q\left(\mathbf{A}{f 16}\right) Q\left(\mathbf{B}\right), \end{aligned} $$
Where $Q(\cdot)$ is either absmax or zeropoint quantization and $c_{x_{f 16} }$ and $c_{w_{f 16} }$ are the respective tensorwise scaling constants $s_{x}$ and $s_{w}$ for absmax or $n d_{x}$ and $n d_{w}$ for zeropoint quantization.
Int8 Matrix Multiplication at Scale
The main challenge with quantization methods that use a single scaling constant per tensor is that a single outlier can reduce the quantization precision of all other values. As such, it is desirable to have multiple scaling constants per tensor, such as block-wise constants (Dettmers et al., 2022), so that the effect of that outliers is confined to each block. We improve upon one of the most common ways of blocking quantization, row-wise quantization (Khudia et al., 2021), by using vector-wise quantization, as described in more detail below.
当使用每个张量一个单一缩放常数的量化方法时,主要的挑战是一个异常值可以降低所有其他值的量化精度。因此,希望每个张量有多个缩放常数,例如块内常数(Dettmers等人,2022),这样异常值的影响仅限于每个块。我们改进了最常用的一种分块量化方法,即行内量化(Khudia等人,2021),通过使用下面更详细描述的向量内量化。
To handle the large magnitude outlier features that occur in all transformer layers beyond the 6.7B scale, vector-wise quantization is no longer sufficient. For this purpose, we develop mixedprecision decomposition, where the small number of large magnitude feature dimensions $(\approx 0.1 %)$ are represented in 16-bit precision while the other $99.9 %$ of values are multiplied in 8-bit. Since most entries are still represented in low-precision, we retain about $50 %$ memory reduction compared to 16-bit. For example, for BLOOM-176B, we reduce the memory footprint of the model by $1.96 x$.
为处理在6.7B规模以上的所有Transformers中发生的大幅度异常值特征,向量内量化不再足够。出于这个目的,我们开发了混合精度分解,其中小数量级的大幅度特征维数(约0.1%)以16Bits精度表示,而其他99.9%的值则以8Bits乘法表示。由于大多数条目仍以低精度表示,与16Bits相比,我们保留了约50%的内存减少。例如,对于BLOOM-176B,我们将模型的内存占用减少了1.96倍。
Vector-wise quantization and mixed-precision decomposition are shown in Figure 2. The LLM.int80 method is the combination of absmax vector-wise quantization and mixed precision decomposition.
图2显示了向量内量化和混合精度分解。 LLM.int8()方法是absmax向量内量化和混合精度分解的组合。
Vector-wise Quantization
One way to increase the number of scaling constants for matrix multiplication is to view matrix multiplication as a sequence of independent inner products. Given the hidden states $\mathbf{X}{f 16} \in \mathbb{R}^{b \times h}$ and weight matrix $\mathbf{W} \in \mathbb{R}^{h \times o}$, we can assign a different scaling constant $c_{x_{f 16} }$ to each row of $\mathbf{X}{f 16}$ and $c$ to each column of $\mathbf{W}{f 16}$. To dequantize, we denormalize each inner product result by $1 /\left(c } c_{w_{f 16} }\right)$. For the whole matrix multiplication this is equivalent to denormalization by the outer product $\mathbf{c}{x } \otimes \mathbf{c}{w }$, where $\mathbf{c}{x} \in \mathbb{R}^{s}$ and $\mathbf{c} \in \mathbb{R}^{o}$. As such the full equation for matrix multiplication with row and column constants is given by:
增加矩阵乘法的缩放常数数量的一种方法是将矩阵乘法视为独立内积序列。给定隐藏状态 X_f16 ∈ R^{b×h} 和权重矩阵 W_f16 ∈ R^{h×o},我们可以为 X_f16 的每一行分配不同的缩放常数 cx_f16,为 Wf16 的每一列分配一个缩放常数 cw。为了反量化,我们通过 1/(cxf16 cwf16) 对每个内积结果进行反归一化。对于整个矩阵乘法,这相当于外积 cxf16 ⊗ cwf16 的反归一化,其中 cx ∈ R^s,cw ∈ R^o。因此,具有行和列常数的矩阵乘法的完整方程为: $$ \mathbf{C}{f } \approx \frac{1}{\mathbf{c}{x } \otimes \mathbf{c}{w } } \mathbf{C}{i 32}=S \cdot \mathbf{C}=\mathbf{S} \cdot \mathbf{A}{i 8} \mathbf{B}=\mathbf{S} \cdot Q\left(\mathbf{A}{f 16}\right) Q\left(\mathbf{B}\right) $$
which we term vector-wise quantization for matrix multiplication.
The Core of LLM.int8(): Mixed-precision Decomposition
In our analysis, we demonstrate that a significant problem for billion-scale 8-bit transformers is that they have large magnitude features (columns), which are important for transformer performance and require high precision quantization. However, vector-wise quantization, our best quantization technique, quantizes each row for the hidden state, which is ineffective for outlier features. Luckily, we see that these outlier features are both incredibly sparse and systematic in practice, making up only about $0.1 %$ of all feature dimensions, thus allowing us to develop a new decomposition technique that focuses on high precision multiplication for these particular dimensions.
我们的分析表明,对于十亿级别的 8Bits Transformers 模型,一个重要问题是它们具有大幅度特征(列),这些特征对于Transformers 模型性能非常重要,需要高精度量化。然而,矢量量化是我们最佳的量化技术,它为隐藏状态的每一行进行量化,但对于异常值特征来说并不起作用。幸运的是,在实践中,我们发现这些异常值特征非常稀疏和系统化,仅占所有特征维度的约0.1%,因此我们可以开发一种新的分解技术,专注于针对这些特定维度实现高精度乘法。
We find that given input matrix $\mathbf{X}{f 16} \in \mathbb{R}^{s \times h}$, these outliers occur systematically for almost all sequence dimensions $s$ but are limited to specific feature/hidden dimensions $h$. As such, we propose mixed-precision decomposition for matrix multiplication where we separate outlier feature dimensions into the set $O={i \mid i \in \mathbb{Z}, 0 \leq i \leq h}$, which contains all dimensions of $h$ which have at least one outlier with a magnitude larger than the threshold $\alpha$. In our work, we find that $\alpha=6.0$ is sufficient to reduce transformer performance degradation close to zero. Using Einstein notation where all indices are superscripts, given the weight matrix $\mathbf{W} \in \mathbb{R}^{h \times o}$, mixed-precision decomposition for matrix multiplication is defined as follows:
我们发现,给定输入矩阵Xf16∈Rs×h,这些异常值特征在几乎所有序列维度s上都是系统性存在的,但仅限于特定的特征/隐藏维度h。因此,我们提出了矩阵乘法的混合精度分解,其中我们将异常值特征维度分离成集合O = {i | i ∈ Z,0 ≤ i ≤ h},其中包含至少有一个幅度大于阈值α的异常值的所有h维度。在我们的工作中,我们发现α = 6.0足以将Transformers 模型性能降低到接近零的程度。在爱因斯坦符号表示法中,其中所有下标都是上标时,给定权重矩阵Wf16∈R h×o,矩阵乘法的混合精度分解定义如下: $$ \mathbf{C}{f 16} \approx \sum{h \in O} \mathbf{X}{f 16}^{h} \mathbf{W}^{h}+\mathbf{S}{f 16} \cdot \sum{h \notin O} \mathbf{X}{i 8}^{h} \mathbf{W}^{h} $$
where $\mathbf{S}{f 16}$ is the denormalization term for the Int8 inputs and weight matrices $\mathbf{X}$ and $\mathbf{W}_{i 8}$.
This separation into 8-bit and 16-bit allows for high-precision multiplication of outliers while using memory-efficient matrix multiplication with 8-bit weights of more than $99.9 %$ of values. Since the number of outlier feature dimensions is not larger than 7 ( $|O| \leq 7$ ) for transformers up to 13B parameters, this decomposition operation only consumes about $0.1 %$ additional memory.
这种分离为 8 位和 16 位允许高精度乘以异常值,同时使用 8 位权重超过 99.9% 值的内存高效矩阵乘法。由于最多 13B 参数的变压器的异常值特征维数不超过 7 (|O| ≤ 7),因此这种分解操作仅使用了大约 0.1% 的额外内存。
Experimental Setup
We measure the robustness of quantization methods as we scale the size of several publicly available pretrained language models up to 175B parameters. The key question is not how well a quantization method performs for a particular model but the trend of how such a method performs as we scale.
我们通过将几个公开可用的预训练语言模型的大小扩展到175B参数来衡量量化方法的健壮性。关键问题不是量化方法在特定模型上表现如何,而是随着扩展模型规模,该方法的性能趋势如何。
We use two setups for our experiments. One is based on language modeling perplexity, which we find to be a highly robust measure that is very sensitive to quantization degradation. We use this setup to compare different quantization baselines. Additionally, we evaluate zeroshot accuracy degradation on OPT models for a range of different end tasks, where we compare our methods with a 16-bit baseline.
我们使用两种实验设置进行实验。一种基于语言建模困惑度的设置,我们发现这是一种非常稳健且对量化退化非常敏感的度量方法。我们使用此设置比较不同量化基线。此外,我们还评估了OPT模型在多种不同端任务上的零样本精度退化情况,其中我们将我们的方法与16Bits基准进行比较。
For the language modeling setup, we use dense autoregressive transformers pretrained in fairseq $(\mathrm{Ott}$ et al., 2019) ranging between 125M and 13B parameters. These transformers have been pretrained on Books (Zhu et al., 2015), English Wikipedia, CC-News (Nagel, 2016), OpenWebText (Gokaslan and Cohen, 2019), CC-Stories (Trinh and Le, 2018), and English CC100 (Wenzek et al., 2020). For more information on how these pretrained models are trained, see Artetxe et al. (2021).
对于语言建模设置,我们使用fairseq中预训练的密集自回归Transformers 模型,涵盖125M到13B个参数。这些Transformers 模型已经在书籍(Zhu等人,2015)、英文维基百科、CC-News(Nagel,2016)、OpenWebText(Gokaslan和Cohen,2019)、CC-Stories(Trinh和Le,2018)和英文CC100(Wenzek等人,2020)上进行了预训练。有关这些预训练模型如何训练的更多信息,请参见Artetxe等人(2021)。
To evaluate the language modeling degradation after Int8 quantization, we evaluate the perplexity of the 8-bit transformer on validation data of the C4 corpus (Raffel et al., 2019) which is a subset of the Common Crawl corpus. ${ }^{5}$ We use NVIDIA A40 GPUs for this evaluation.
为了评估Int8量化后语言建模的退化情况,我们在C4语料库(Raffel等人,2019)的验证数据上评估8BitsTransformers 模型的困惑度。C4语料库是Common Crawl语料库的子集。我们使用NVIDIA A40 GPU进行此评估。
To measure degradation in zeroshot performance, we use OPT models (Zhang et al., 2022), and we evaluate these models on the EleutherAI language model evaluation harness (Gao et al., 2021).
为了测量零样本性能的退化情况,我们使用OPT模型(Zhang等人,2022),并在EleutherAI语言模型评估平台(Gao等人,2021)上评估这些模型。
Main Results
The main language modeling perplexity results on the $125 \mathrm{M}$ to 13B Int8 models evaluated on the $\mathrm{C} 4$ corpus can be seen in Table 1. We see that absmax, row-wise, and zeropoint quantization fail as we scale, where models after 2.7B parameters perform worse than smaller models. Zeropoint quantization fails instead beyond 6.7B parameters. Our method, LLM.int8(), is the only method that preserves perplexity. As such, LLM.int8() is the only method with a favorable scaling trend.
该研究的主要结果是,LLM.int8()是唯一能够在模型大小增加时保持困惑度的量化方法,而其他方法(如absmax、row-wise、vector-wise 和zeropoint量化)都会导致显著的性能下降。该研究评估了大小从125M到13B个参数的Int8模型在C4语料库上的表现,并发现其他方法随着模型规模的增大而失败,模型超过2.7B参数后表现比较小的模型更差。Zeropoint量化在6.7B参数之后也失败了。只有LLM.int8()能够在模型大小增加时保持困惑度不变,使其成为具有良好缩放趋势的唯一方法。Zeropoint量化由于其非对称量化具有优势,但在与混合精度分解一起使用时不再具有优势。
Table 1: C4 validation perplexities of quantization methods for different transformer sizes ranging from 125M to 13B parameters. We see that absmax, row-wise, zeropoint, and vector-wise quantization leads to significant performance degradation as we scale, particularly at the 13B mark where 8-bit 13B perplexity is worse than 8-bit 6.7B perplexity. If we use LLM.int8(), we recover full perplexity as we scale. Zeropoint quantization shows an advantage due to asymmetric quantization but is no longer advantageous when used with mixed-precision decomposition.
When we look at the scaling trends of zeroshot performance of OPT models on the EleutherAI language model evaluation harness in Figure 1, we see that LLM.int8() maintains full 16-bit performance as we scale from 125M to 175B parameters. On the other hand, the baseline, 8-bit absmax vector-wise quantization, scales poorly and degenerates into random performance.
当我们看一下EleutherAI上OPT模型的零点性能的扩展趋势时, 语言模型评估线束时,我们看到LLM.int8()在我们将参数从125M扩展到175B时保持了完整的16位性能。另一方面,基线,8位absmax 矢量量化,扩展性很差,并退化为随机性能。
Although our primary focus is on saving memory, we also measured the run time of LLM.int8(). The quantization overhead can slow inference for models with less than 6.7B parameters, as compared to a FP16 baseline. However, models of 6.7B parameters or less fit on most GPUs and quantization is less needed in practice. LLM.int8() run times is about two times faster for large matrix multiplications equivalent to those in 175B models. Appendix D provides more details on these experiments.
虽然我们主要关注的是节省内存,但我们也测量了LLM.int8()的运行时间。量化开销与FP16基线相比,量化开销会使参数少于6.7B的模型的推理速度变慢。 FP16基线。然而,6.7B参数或更少的模型适合在大多数GPU上运行,量化在实践中不太需要。 在实践中不太需要。LLM.int8()的运行时间比175B模型中的大型矩阵乘法快2倍左右。 相当于175B模型中的那些。附录D提供了关于这些实验的更多细节。
Emergent Large Magnitude Features in Transformers at Scale
As we scale transformers, outlier features with large magnitudes emerge and strongly affect all layers and their quantization. Given a hidden state $\mathbf{X} \in \mathbb{R}^{s \times h}$ where $s$ is the sequence/token dimension and $h$ the hidden/feature dimension, we define a feature to be a particular dimension $h_{i}$. Our analysis looks at a particular feature dimension $h_{i}$ across all layers of a given transformer.
随着我们对Transformers 的扩展,具有较大幅度的离群特征会出现,并强烈影响到所有层和它们的量化。给定一个隐藏状态X∈R s×h,其中s是序列/Token维度,而 h是隐藏/特征维度,我们将一个特征定义为一个特定的维度hi . 我们的分析着眼于一个特定的特征维度hi,跨越一个给定的转化器的所有层。
We find that outlier features strongly affect attention and the overall predictive performance of transformers. While up to 150k outliers exist per 2048 token sequence for a 13B model, these outlier features are highly systematic and only representing at most 7 unique feature dimensions $h_{i}$. Insights from this analysis were critical to developing mixed-precision decomposition. Our analysis explains the advantages of zeropoint quantization and why they disappear with the use of mixed-precision decomposition and the quantization performance of small vs. large models.
我们发现,离群的特征强烈地影响了注意力和Transformers 的整体预测性能。 Transformers 的整体预测性能。虽然对于一个13B的模型来说,每个2048 个符号序列存在多达150k个离群点,但这些离群点特征是高度系统化的,最多只能代表7个独特的特征维度。 从这个分析中得到的启示这一分析对于开发混合精度分解至关重要。我们的分析解释了零点量化的优势,以及为什么这些优势在使用混合精度分解的情况下会消失。 分解,以及小模型与大模型的量化性能。
Finding Outlier Features
The difficulty with the quantitative analysis of emergent phenomena is two-fold. We aim to select a small subset of features for analysis such that the results are intelligible and not to complex while also capturing important probabilistic and structured patterns. We use an empirical approach to find these constraints. We define outliers according to the following criteria: the magnitude of the feature is at least 6.0 , affects at least $25 %$ of layers, and affects at least $6 %$ of the sequence dimensions.
对涌现现象进行定量分析的困难有两方面。我们的目标是选择一小部分特征进行分析,以便结果易于理解且不复杂,同时还能捕获重要的概率和结构化模式。我们使用经验方法来找到这些约束。我们根据以下标准定义异常值:特征的大小至少为 6.0 ,至少影响25%层数,并且至少影响6%的序列维度。
More formally, given a transformer with $L$ layers and hidden state $\mathbf{X}{l} \in \mathbb{R}^{s \times h}, l=0 \ldots L$ where $s$ is the sequence dimension and $h$ the feature dimension, we define a feature to be a particular dimension $h$ in any of the hidden states $\mathbf{X}{l }$. We track dimensions $h_{i}, 0 \leq i \leq h$, which have at least one value with a magnitude of $\alpha \geq 6$ and we only collect statistics if these outliers occur in the same feature dimension $h_{i}$ in at least $25 %$ of transformer layers $0 \ldots L$ and appear in at least $6 %$ of all sequence dimensions $s$ across all hidden states $\mathbf{X}_{l}$. Since feature outliers only occur in attention projection
(a)

(b)
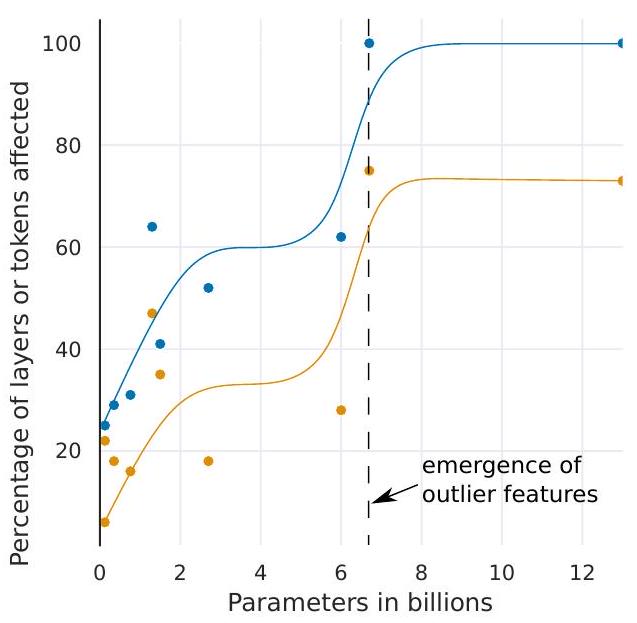
Figure 3: Percentage of layers and all sequence dimensions affected by large magnitude outlier features across the transformer by (a) model size or (b) $\mathrm{C} 4$ perplexity. Lines are B-spline interpolations of 4 and 9 linear segments for (a) and (b). Once the phase shift occurs, outliers are present in all layers and in about $75 %$ of all sequence dimensions. While (a) suggest a sudden phase shift in parameter size, (b) suggests a gradual exponential phase shift as perplexity decreases. The stark shift in (a) co-occurs with the sudden degradation of performance in quantization methods.
图 3:受 (a) 模型大小或 (b) 影响的大量异常值特征影响的层百分比和所有序列维度C4C 4困惑。线是 (a) 和 (b) 的 4 和 9 线性段的 B 样条插值。一旦发生相移,所有层和大约75%75%所有序列维度。虽然 (a) 表明参数大小的突然相移,但 (b) 表明随着困惑度的降低逐渐呈指数相移。(a) 中的明显转变与量化方法性能的突然下降同时发生。
(key/query/value/output) and the feedforward network expansion layer (first sub-layer), we ignore the attention function and the FFN contraction layer (second sub-layer) for this analysis.
Our reasoning for these thresholds is as follows. We find that using mixed-precision decomposition, perplexity degradation stops if we treat any feature with a magnitude 6 or larger as an outlier feature. For the number of layers affected by outliers, we find that outlier features are systematic in large models: they either occur in most layers or not at all. On the other hand, they are probabilistic in small models: they occur sometimes in some layers for each sequence. As such, we set our threshold for how many layers need to be affected to detect an outlier feature in such a way as to limit detection to a single outlier in our smallest model with $125 \mathrm{M}$ parameters. This threshold corresponds to that at least $25 %$ of transformer layers are affected by an outlier in the same feature dimension. The second most common outlier occurs in only a single layer ( $2 %$ of layers), indicating that this is a reasonable threshold. We use the same procedure to find the threshold for how many sequence dimensions are affected by outlier features in our $125 \mathrm{M}$ model: outliers occur in at least $6 %$ of sequence dimensions.
我们对这些阈值的推理如下。我们发现,使用混合精度分解,如果我们将任何 6 级或更大的特征视为离群特征,则困惑退化停止。对于受异常值影响的层数,我们发现异常值特征在大型模型中是系统的:它们要么出现在大多数层中,要么根本不出现。另一方面,它们在小模型中是概率性的:它们有时会出现在每个序列的某些层中。因此,我们设置了需要影响多少层的阈值以检测异常值特征,从而将检测限制在我们最小模型中的单个异常值125M参数。这个阈值对应于至少25%的Transformers层受到同一特征维度中的异常值的影响。第二个最常见的异常值仅出现在一个层中(2%层数),表明这是一个合理的阈值。我们使用相同的程序来找到我们的异常特征影响多少序列维度的阈值125M模型:异常值至少出现在6%序列维度。
We test models up to a scale of 13B parameters. To make sure that the observed phenomena are not due to bugs in software, we evaluate transformers that were trained in three different software frameworks. We evaluate four GPT-2 models which use OpenAI software, five Meta AI models that use Fairseq (Ott et al., 2019), and one EleutherAI model GPT-J that uses Tensorflow-Mesh (Shazeer et al., 2018). More details can be found in Appendix C. We also perform our analysis in two different inference software frameworks: Fairseq and Hugging Face Transformers (Wolf et al., 2019).
我们测试了高达 13B 参数规模的模型。为了确保观察到的现象不是由软件错误引起的,我们评估了在三种不同软件框架中训练的变压器。我们评估了四个使用 OpenAI 软件的 GPT-2 模型、五个使用 Fairseq 的 Meta AI 模型(Ott 等人,2019 年)和一个使用 Tensorflow-Mesh 的 EleutherAI 模型 GPT-J(Shazeer 等人,2018 年)。更多详细信息可以在附录 C 中找到。我们还在两个不同的推理软件框架中执行我们的分析:Fairseq 和 Hugging Face Transformers(Wolf 等人,2019)。
Measuring the Effect of Outlier Features
To demonstrate that the outlier features are essential for attention and predictive performance, we set the outlier features to zero before feeding the hidden states $\mathbf{X}_{l}$ into the attention projection layers and then compare the top-1 softmax probability with the regular softmax probability with outliers. We do this for all layers independently, meaning we forward the regular softmax probabilities values to avoid cascading errors and isolate the effects due to the outlier features. We also report the perplexity degradation if we remove the outlier feature dimension (setting them to zero) and propagate these altered, hidden states through the transformer. As a control, we apply the same procedure for random non-outlier feature dimensions and note attention and perplexity degradation.
为了证明异常值特征对于注意力和预测性能至关重要,我们在提供隐藏状态之前将异常值特征设置为零, 在 X进入注意投影层之前,然后将 top-1 softmax 概率与带有异常值的常规 softmax 概率进行比较。我们独立地对所有层执行此操作,这意味着我们转发常规 softmax 概率值以避免级联错误并隔离由于异常值特征引起的影响。如果我们删除离群特征维度(将它们设置为零)并通过转换器传播这些改变的隐藏状态,我们还会报告困惑度下降。作为对照,我们对随机非离群特征维度应用相同的程序,并注意注意力和困惑退化。
Our main quantitative results can be summarized as four main points.
(a)
(b)
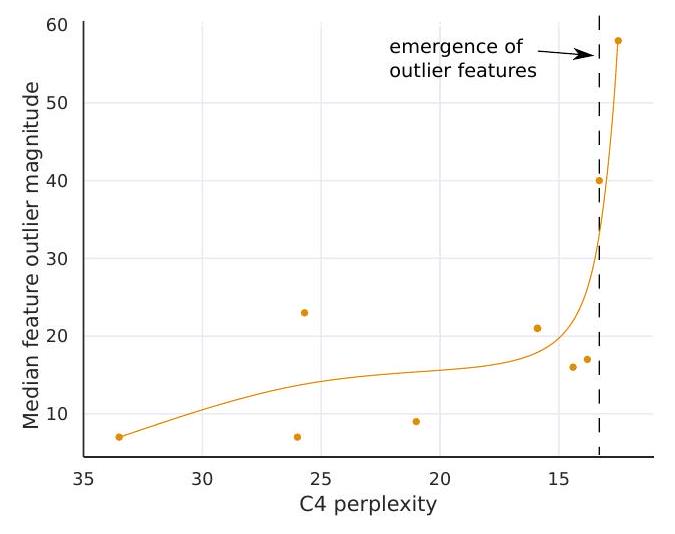
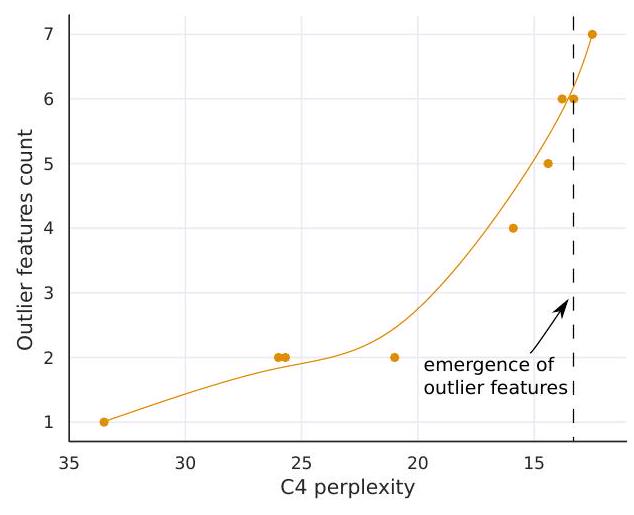
Figure 4: The median magnitude of the largest outlier feature in (a) indicates a sudden shift in outlier size. This appears to be the prime reason why quantization methods fail after emergence. While the number of outlier feature dimensions is only roughly proportional to model size, (b) shows that the number of outliers is strictly monotonic with respect to perplexity across all models analyzed. Lines are B-spline interpolations of 9 linear segments.
我们的主要定量结果可以概括为四个要点。
图 4:(a) 中最大异常值特征的中值大小表明异常值大小突然发生变化。这似乎是量化方法出现后失败的主要原因。虽然异常值特征维度的数量仅与模型大小大致成正比,但 (b) 表明异常值的数量在所有分析的模型中的困惑度方面严格单调。直线是 9 条直线段的 B 样条插值。
(1) When measured by the number of parameters, the emergence of large magnitude features across all layers of a transformer occurs suddenly between 6B and 6.7B parameters as shown in Figure 3a as the percentage of layers affected increases from $65 %$ to $100 %$. The number of sequence dimensions affected increases rapidly from $35 %$ to $75 %$. This sudden shift co-occurs with the point where quantization begins to fail.
(1) 当用参数数量来衡量时,如图 3a 所示,随着受影响层的百分比从65%到100%. 受影响的序列维数从35%到75%. 这种突然的转变与量化开始失败的点同时发生。
(2) Alternatively, when measured by perplexity, the emergence of large magnitude features across all layers of the transformer can be seen as emerging smoothly according to an exponential function of decreasing perplexity, as seen in Figure 3b. This indicates that there is nothing sudden about emergence and that we might be able to detect emergent features before a phase shift occurs by studying exponential trends in smaller models. This also suggests that emergence is not only about model size but about perplexity, which is related to multiple additional factors such as the amount of training data used, and data quality (Hoffmann et al., 2022; Henighan et al., 2020).
(2) 或者,当用困惑度来衡量时,transformer 所有层中大量特征的出现可以看作是根据困惑度递减的指数函数平滑出现的,如图 3b 所示。这表明涌现并不是突然发生的,我们可以通过研究较小模型的指数趋势,在相移发生之前检测到涌现特征。这也表明,涌现不仅与模型大小有关,还与困惑度有关,这与使用的训练数据量和数据质量等多个附加因素有关(Hoffmann 等人,2022 年;Henighan 等人,2020 年)。
(3) Median outlier feature magnitude rapidly increases once outlier features occur in all layers of the transformer, as shown in Figure 4a. The large magnitude of outliers features and their asymmetric distribution disrupts Int8 quantization precision. This is the core reason why quantization methods fail starting at the 6.7B scale - the range of the quantization distribution is too large so that most quantization bins are empty and small quantization values are quantized to zero, essentially extinguishing information. We hypothesize that besides Int8 inference, regular 16-bit floating point training becomes unstable due to outliers beyond the 6.7B scale - it is easy to exceed the maximum 16-bit value 65535 by chance if you multiply by vectors filled with values of magnitude 60 .
(3) 一旦异常值特征出现在transformer的所有层中,中值异常值特征幅度迅速增加,如图4a所示。大量异常值特征及其不对称分布破坏了 Int8 量化精度。这是量化方法从 6.7B 尺度开始失败的核心原因——量化分布的范围太大,以至于大多数量化仓为空,小的量化值被量化为零,基本上消除了信息。我们假设除了 Int8 推理之外,常规的 16 位浮点训练由于超出 6.7B 尺度的异常值而变得不稳定 - 如果乘以填充了 60 大小的值的向量,很容易偶然超过最大 16 位值 65535 .
(4) The number of outliers features increases strictly monotonically with respect to decreasing C4 perplexity as shown in Figure 4b, while a relationship with model size is non-monotonic. This indicates that model perplexity rather than mere model size determines the phase shift. We hypothesize that model size is only one important covariate among many that are required to reach emergence.
(4) 如图 4b 所示,异常值特征的数量相对于 C4 困惑度的降低严格单调增加,而与模型大小的关系是非单调的。这表明模型的复杂性而不是模型的大小决定了相移。我们假设模型大小只是实现出现所需的众多协变量中的一个重要协变量。
These outliers features are highly systematic after the phase shift occurred. For example, for a 6.7B transformer with a sequence length of 2048, we find about 150k outlier features per sequence for the entire transformer, but these features are concentrated in only 6 different hidden dimensions.
这些异常值特征在发生相移后具有高度的系统性。例如,对于序列长度为 2048 的 6.7B 转换器,我们发现整个转换器的每个序列大约有 150k 个异常值特征,但这些特征仅集中在 6 个不同的隐藏维度中。
These outliers are critical for transformer performance. If the outliers are removed, the mean top-1 softmax probability is reduced from about $40 %$ to about $20 %$, and validation perplexity increases by 600-1000% even though there are at most 7 outlier feature dimensions. When we remove 7 random feature dimensions instead, the top-1 probability decreases only between $0.02-0.3 %$, and perplexity increases by $0.1 %$. This highlights the critical nature of these feature dimensions. Quantization precision for these outlier features is paramount as even tiny errors greatly impact model performance.
这些异常值对变压器性能至关重要。如果移除异常值,则平均 top-1 softmax 概率从大约降低40%大概20%,即使最多有 7 个离群特征维度,验证困惑度也会增加 600-1000%。当我们移除 7 个随机特征维度时,top-1 概率仅在0.02−0.3%,困惑度增加0.1%. 这突出了这些特征维度的关键性质。这些离群特征的量化精度至关重要,因为即使是微小的错误也会极大地影响模型性能。
Interpretation of Quantization Performance
Our analysis shows that outliers in particular feature dimensions are ubiquitous in large transformers, and these feature dimensions are critical for transformer performance. Since row-wise and vectorwise quantization scale each hidden state sequence dimension $s$ (rows) and because outliers occur in the feature dimension $h$ (columns), both methods cannot deal with these outliers effectively. This is why absmax quantization methods fail quickly after emergence.
However, almost all outliers have a strict asymmetric distribution: they are either solely positive or negative (see Appendix C). This makes zeropoint quantization particularly effective for these outliers, as zeropoint quantization is an asymmetric quantization method that scales these outliers into the full $[-127,127]$ range. This explains the strong performance in our quantization scaling benchmark in Table 1. However, at the 13B scale, even zeropoint quantization fails due to accumulated quantization errors and the quick growth of outlier magnitudes, as seen in Figure 4a.
If we use our full LLM.int8() method with mixed-precision decomposition, the advantage of zeropoint quantization disappears indicating that the remaining decomposed features are symmetric. However, vector-wise still has an advantage over row-wise quantization, indicating that the enhanced quantization precision of the model weights is needed to retain full precision predictive performance.
Related work
There is closely related work on quantization data types and quantization of transformers, as described below. Appendix B provides further related work on quantization of convolutional networks.
8-bit Data Types. Our work studies quantization techniques surrounding the Int8 data type, since it is currently the only 8-bit data type supported by GPUs. Other common data types are fixed point or floating point 8-bit data types (FP8). These data types usually have a sign bit and different exponent and fraction bit combinations. For example, a common variant of this data type has 5 bits for the exponent and 2 bits for the fraction (Wang et al., 2018; Sun et al., 2019; Cambier et al., 2020; Mellempudi et al., 2019) and uses either no scaling constants or zeropoint scaling. These data types have large errors for large magnitude values since they have only 2 bits for the fraction but provide high accuracy for small magnitude values. Jin et al. (2022) provide an excellent analysis of when certain fixed point exponent/fraction bit widths are optimal for inputs with a particular standard deviation. We believe FP8 data types offer superior performance compared to the Int8 data type, but currently, neither GPUs nor TPUs support this data type.
Outlier Features in Language Models. Large magnitude outlier features in language models have been studied before (Timkey and van Schijndel, 2021; Bondarenko et al., 2021; Wei et al., 2022; Luo et al., 2021). Previous work proved the theoretical relationship between outlier appearance in transformers and how it relates to layer normalization and the token frequency distribution (Gao et al., 2019). Similarly, Kovaleva et al. (2021) attribute the appearance of outliers in BERT model family to LayerNorm, and Puccetti et al. (2022) show empirically that outlier emergence is related to the frequency of tokens in the training distribution. We extend this work further by showing how the scale of autoregressive models relates to the emergent properties of these outlier features, and showing how appropriately modeling outliers is critical to effective quantization.
Multi-billion Scale Transformer Quantization. There are two methods that were developed in parallel to ours: nuQmm (Park et al., 2022) and ZeroQuant (Yao et al., 2022). Both use the same quantization scheme: group-w2ise quantization, which has even finer quantization normalization constant granularity than vector-wise quantization. This scheme offers higher quantization precision but also requires custom CUDA kernels. Both nuQmm and ZeroQuant aim to accelerate inference and reduce the memory footprint while we focus on preserving predictive performance under an 8-bit memory footprint. The largest models that nuQmm and ZeroQuant evaluate are 2.7B and 20B parameter transformers, respectively. ZeroQuant achieves zero-degradation performance for 8-bit quantization of a 20B model. We show that our method allows for zero-degradation quantization of models up to 176B parameters. Both nuQmm and ZeroQuant suggest that finer quantization granularity can be an effective means to quantize large models. These methods are complementary with LLM.int8(). Another parallel work is GLM-130B which uses insights from our work to achieve zero-degradation 8-bit quantization (Zeng et al., 2022). GLM-130B performs full 16-bit precision matrix multiplication with 8-bit weight storage.
Discussion and Limitations
We have demonstrated for the first time that multi-billion parameter transformers can be quantized to Int8 and used immediately for inference without performance degradation. We achieve this by using our insights from analyzing emergent large magnitude features at scale to develop mixed-precision decomposition to isolate outlier features in a separate 16-bit matrix multiplication. In conjunction with vector-wise quantization that yields our method, LLM.int8(), which we show empirically can recover the full inference performance of models with up to 175B parameters.
The main limitation of our work is that our analysis is solely on the Int8 data type, and we do not study 8-bit floating-point (FP8) data types. Since current GPUs and TPUs do not support this data type, we believe this is best left for future work. However, we also believe many insights from Int8 data types will directly translate to FP8 data types. Another limitation is that we only study models with up to $175 \mathrm{~B}$ parameters. While we quantize a 175B model to Int8 without performance degradation, additional emergent properties might disrupt our quantization methods at larger scales.
A third limitation is that we do not use Int8 multiplication for the attention function. Since our focus is on reducing the memory footprint and the attention function does not use any parameters, it was not strictly needed. However, an initial exploration of this problem indicated that a solution required additional quantization methods beyond those we developed here, and we leave this for future work.
A final limitation is that we focus on inference but do not study training or finetuning. We provide an initial analysis of Int8 finetuning and training at scale in Appendix E. Int8 training at scale requires complex trade-offs between quantization precision, training speed, and engineering complexity and represents a very difficult problem. We again leave this to future work.
Table 2: Different hardware setups and which methods can be run in 16-bit vs. 8-bit precision. We can see that our 8-bit method makes many models accessible that were not accessible before, in particular, OPT-175B/BLOOM.
tabular
{lllcc} \hline & & & \multicolumn{2}{c}{ Largest Model that can be run } \ \cline { 3 - 5 } Class & Hardware & GPU Memory & 8-bit & 16-bit \ \hline Enterprise & $8 x$ A100 & $80 \mathrm{~GB}$ & OPT-175B / BLOOM & OPT-175B / BLOOM \ Enterprise & $8 x$ A100 & $40 \mathrm{~GB}$ & OPT-175B / BLOOM & OPT-66B \ Academic server & 8x RTX 3090 & $24 \mathrm{~GB}$ & OPT-175B / BLOOM & OPT-66B \ Academic desktop & 4x RTX 3090 & 24 GB & OPT-66B & OPT-30B \ Paid Cloud & Colab Pro & $15 \mathrm{~GB}$ & OPT-13B & GPT-J-6B \ Free Cloud & Colab & $12 \mathrm{~GB}$ & T0/T5-11B & GPT-2 1.3B \ \hline \end
Broader Impacts
The main impact of our work is enabling access to large models that previously could not fit into GPU memory. This enables research and applications which were not possible before due to limited GPU memory, in particular for researchers with the least resources. See Table 3 for model/GPU combinations which are now accessible without performance degradation. However, our work also enables resource-rich organizations with many GPUs to serve more models on the same number of GPUs, which might increase the disparities between resource-rich and poor organizations.
In particular, we believe that the public release of large pretrained models, for example, the recent Open Pretrained Transformers (OPT) (Zhang et al., 2022), along with our new Int8 inference for zeroand few-shot prompting, will enable new research for academic institutions that was not possible before due to resource constraints. The widespread accessibility of such large-scale models will likely have both beneficial and detrimental effects on society that are difficult to predict.
Acknowledgments We thank Ofir Press, Gabriel Ilharco, Daniel Jiang, Mitchell Wortsman, Ari Holtzman, Mitchell Gordon for their feedback on drafts of this work. We thank JustHeuristic (Yozh) and Titus von Köller for help with Hugging Face Transformers integration.