Wide & Deep
Introduction
与传统搜索类似,推荐系统的一个挑战是如何同时获得推荐结果准确性和扩展性。推荐的内容都是精准内容,用户兴趣收敛,无新鲜感,不利于长久的用户留存;推荐内容过于泛化,用户的精准兴趣无法得到满足,用户流失风险很大。相比较推荐的准确性,扩展性倾向与改善推荐系统的多样性。
Wide & Deep的主要特点: 本文提出Wide & Deep模型,旨在使得训练得到的模型能够同时获得记忆(memorization)和泛化(generalization)能力:
记忆(memorization)即从历史数据中发现item或者特征之间的相关性;哪些特征更重要——Wide部分。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合;——Deep部分。 在推荐系统中,记忆体现的准确性,而泛化体现的是新颖性。

首先,他模型發展的目標主要是希望解決檢索排序問題,並達到Memorization以及Generalization。
Memorization主要的定義其實就是透過歷史資料進行學習,透過歷史曾經發生的關係,達到精準預測(將歷史資料發揮淋漓盡致)。
Generalization主要的定義是希望透過這個模型找到新的特徵組合,而過去很少發生,因此此模型主要是增加預測結果的diversity。 
wide model
此篇的寬模型,主要是使用GLM中的LR(經典的CTR預測模型)。優點是模型簡單、Scalable(Spark MLlib已經有開源,可直接call api)、可解釋性等優點。所以工程師可以專注於處理特徵,打造特徵海(寬的原因)。常使用One -hot encoding作為feature、且可使用一些無直接相關的特徵(Ex: 安裝app類別)。
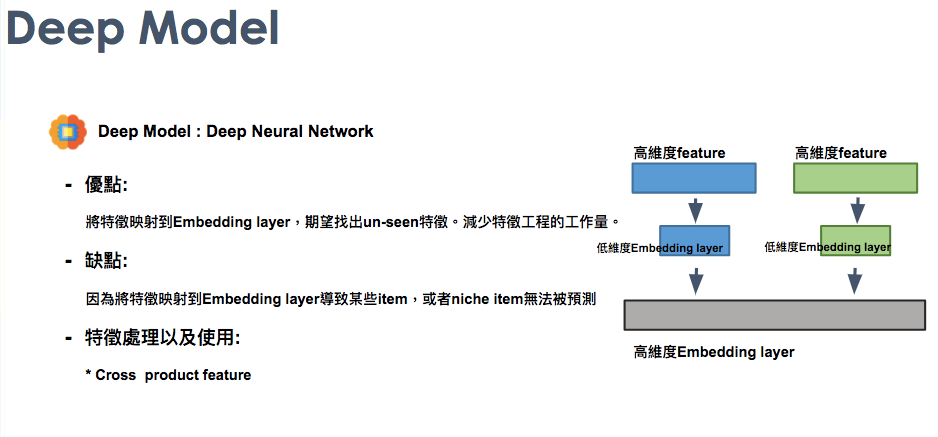
Deep Model
此篇的深模型,主要是使用DNN,而他使用的方式先將大量高維度的矩陣先映射到Embedding layer,希望透過這個方式能找到一些隱藏特徵。這樣的模型有一個很大的優點就是減少工程師花在特徵工程的時間。缺點的部分就是因為將高維度映射到一個較低維度的 Embedding layer,也就是說透過32維度來表示可能原來1萬維度的是否安裝什麼樣的app這個維度。致使一些資訊合併,讓某些item 或者niche item無法被預測。而這樣的Model常使用一些Cross product feature於推薦系統。
Model

Wide部分
Wide Model主要是使用Logistic Regression,一般來說就是權重X特徵+偏差,並丟入sigmoid function,最後就是預測是否的機率。在文章中,主要是使用cross product feature(Ex: 是否安裝app以及接下來點擊什麼樣的app),與前面wide model的任務呼應,就是希望找出新的產品組合,此外就是增加一些非線性。


Wide Model optimizer
其中LR的optimizer跟過去不一樣,過去都是使用SGD,而在Wide Model他是使用2013 Google在KDD上發表的文章(FTRL更早就有被發表),FTRL主要是對gradient進行微調,在Wt+1 step中,對第一步跟當下算出來的weight進行minnium,也就是說希望新的解跟當下算出來的解不要差太遠,讓gradient步伐小一點。此外他也要加入L1 regularization,讓找出的解稀疏一點。
wide部分就是一个广义线性模型,输入主要由两部分,一部分是原始特征,另一部分是交互特征,我们可以通过cross-product transformation的形式来构造K组交互特征:
$$ \phi _ { k } ( \mathbf { x } ) = \prod _ { i = 1 } ^ { d } x _ { i } ^ { c _ { k i } } \quad c _ { k i } \in { 0,1 } $$
Deep部分
Deep部分就是一个DNN的模型,每一层计算如下: $$ a ^ { ( l + 1 ) } = f \left( W ^ { ( l ) } a ^ { ( l ) } + b ^ { ( l ) } \right) $$

Deep Neural Network,跟過去的類神經很相似,只是將其中的hidden layer不斷疊深。feature的部分,此篇主要使用numeric or one-hot encoding的feature。
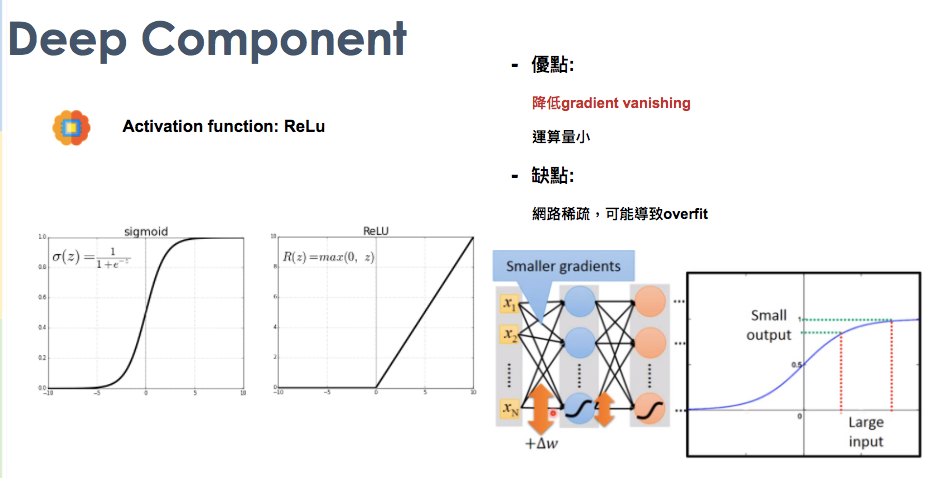
activation function
過去DNN使用的activation function,主要為sigmoid function ,而sigmoid function最大的問題就是會有gradient vanishing,因為當我們的gradient算出來例如:10000,但放入sigmoid function,他會被壓縮,最大值頂多就是1,許多gradient vanishing。因此,當我每進一次sigmoid function,gradient就會衰減一次。很可能最後訓練出來的結果會在local min就停下來,因為gradient太小趨近於0。
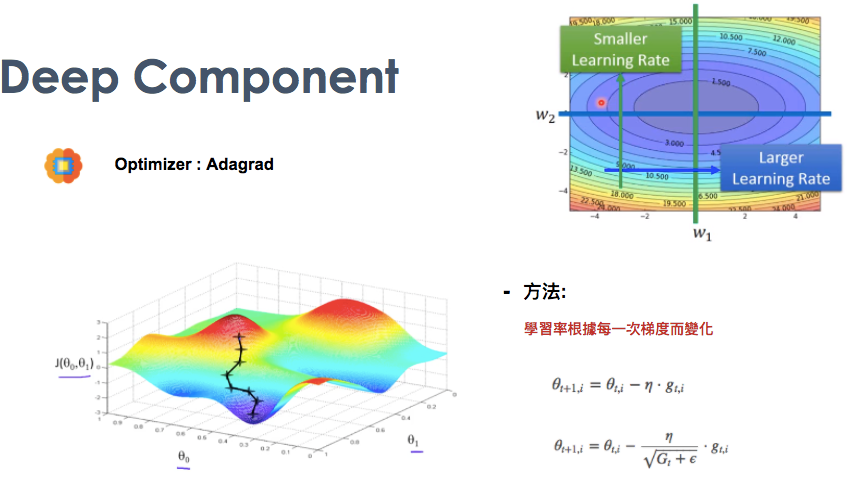
DNN optimizer
文章中,DNN使用的optimizer是adagrad,他主要概念為所有權重應該要有不同的learning rate。從公式可知,在graident大的時候走慢一點(變化很大),gradient小的時候走快一點(變化不大)。
联合训练
Wide & Deep模型采用的是联合训练的形式,而非集成。二者的区别就是联合训练公用一个损失函数,然后同时更新各个部分的参数,而集成方法是独立训练N个模型,然后进行融合。因此,模型的输出为: $$ P ( Y = 1 | \mathbf { x } ) = \sigma \left( \mathbf { w } _ { w i d e } ^ { T } [ \mathbf { x } , \phi ( \mathbf { x } ) ] + \mathbf { w } _ { d e e p } ^ { T } a ^ { \left( l _ { f } \right) } + b \right) $$
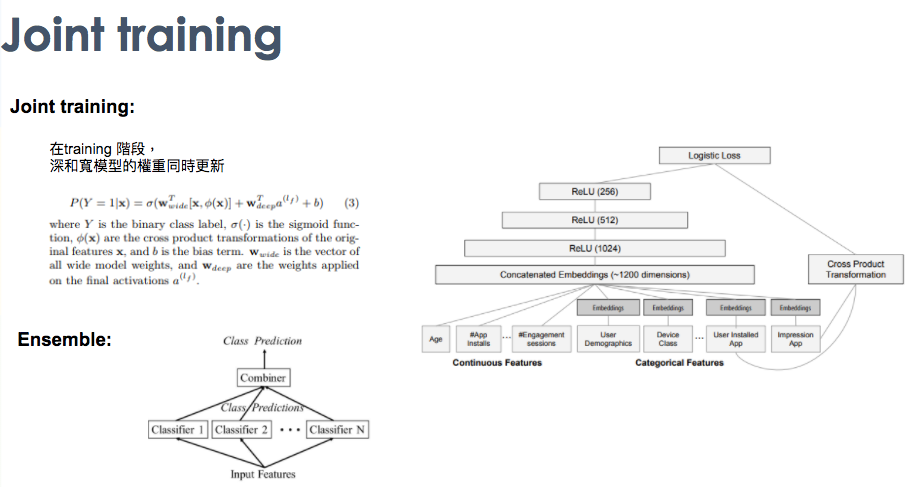
此篇最重要的概念之一就是他的權重是同時更新,而不是像是ensemble一樣各自學習,然後投票出最後的結果。
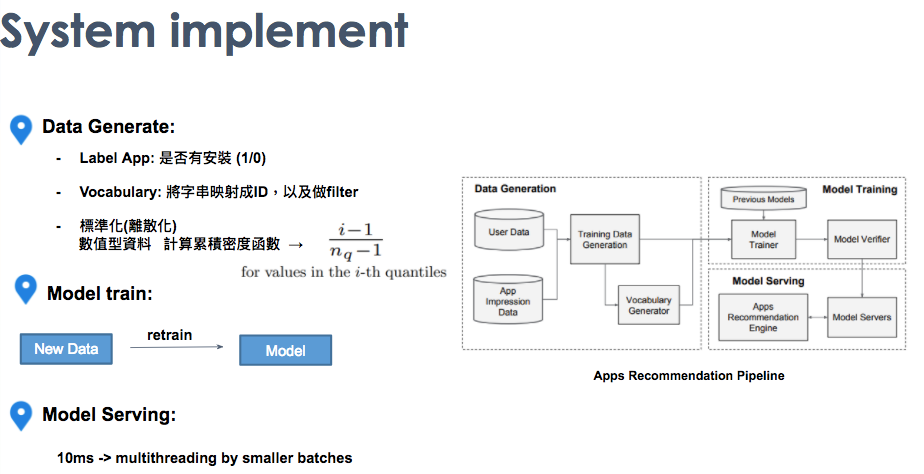
system implement
在整個app recommendation pipeline,它分為三大項,Data Generate, Model train 以及 Model serving。Data Generate的部分主要是做資料前處理,像是one — hot encoding , 字串轉換以及離散化。Model train的部分就是他會做online learning,只要有新的資料進來,他就會將過去的權重拿出來,繼續學習微調權重。Model serving的部分是希望能在10ms去做response,因此他們使用multithreading 以及batch設定進行加速。
Experiment

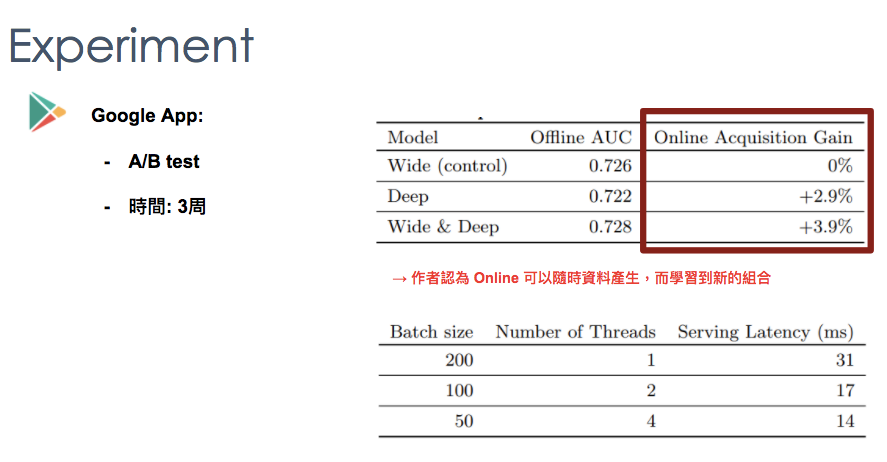
Experiment
最後Google有在google play上實做測試,並使用A/B test進行模型驗證。可發現offline 的auc測出來結果並沒有太大差異。但在線上的收益卻是有較大的成長。而他們認為線上測試,可以隨時有新的資料組合產生,進而去學習。
使用Wide and Deep模型的App推荐系统架构
当一个用户访问app商店时,此时会产生一个请求,请求到达推荐系统后,推荐系统为该用户返回推荐的apps列表。 
在实际的推荐系统中,通常将推荐的过程分为两个部分,即上图中的Retrieval和Ranking,Retrieval负责从数据库中检索出与用户相关的一些apps,Ranking负责对这些检索出的apps打分,最终,按照分数的高低返回相应的列表给用户。
模型的训练之前,最重要的工作是训练数据的准备以及特征的选择,在apps推荐中,可以使用到的数据包括用户和曝光数据。 每一条样本对应了一条曝光数据,同时,样本的标签为1表示安装,0则表示未安装。
对于类别特征,通过词典(Vocabularies)将其映射成向量;对于连续的实数特征,将其归一化到区间[0,1]。
