Deep & Cross Network
DCN全称Deep & Cross Network,是谷歌和斯坦福大学在2017年提出的用于Ad Click Prediction的模型。DCN(Deep Cross Network)在学习特定阶数组合特征的时候效率非常高,而且同样不需要特征工程,引入的额外的复杂度也是微乎其微的。
一、Motivation
针对大规模稀疏特征的点击率预估问题,Google在2016年提出 Wide & Deep 的结构来同时实现Memorization与Generalization(前面介绍过该文,感兴趣的读者可参见 详解 Wide & Deep 结构背后的动机)。但是在Wide部分,仍然需要人工地设计特征叉乘。面对高维稀疏的特征空间、大量的可组合方式,基于人工先验知识虽然可以缓解一部分压力,但仍需要不小的人力和尝试成本,并且很有可能遗漏一些重要的交叉特征。FM可以自动组合特征,但也仅限于二阶叉乘。能否告别人工组合特征,并且自动学习高阶的特征组合呢?Deep & Cross 即是对此的一个尝试。
在Kaggle上的很多比赛中,大部分的获胜方案都是使用的人工特征工程,构造低阶的组合特征,这些特征意义明确且高效。而DNN学习到的特征都是高度非线性的高阶组合特征,含义非常难以解释。那么是否能设计一种DNN的特定网络结构来改善DNN,使得其学习起来更加高效那?
二、DCN特点
DCN特点如下:
- 使用cross network,在每一层都应用feature crossing。高效的学习了bounded degree组合特征。不需要人工特征工程。
- 网络结构简单且高效。多项式复杂度由layer depth决定。
- 相比于DNN,DCN的logloss更低,而且参数的数量将近少了一个数量级。
三、DCN
类似Wide & Deep,Deep & Cross的网络结构如图1所示,可以仔细观察下:

DCN架构图如上图所示:最开始是Embedding and stacking layer,然后是并行的Cross Network和Deep Network,最后是Combination Layer把Cross Network和Deep Network的结果组合得到Output。
Embedding and Stacking Layer
这一层说起来其实非常的简单,就两个功能Embed和Stack。
离散特征嵌入
离散特征嵌入这个想法最初来自于 Mikolov 的 word2vec[5]系列文章。最初解决的问题是词的独热表示过于稀疏,并且不同词之间的向量形式表示完全没有联系。具体思路在此不赘述,最终的实现是将一个上万维的词独热表示嵌入到了只有几百维的稠密向量中。而嵌入的本质其实是构建一张随机初始化的向量查找表,通过我们的训练目标做有监督学习来得到不同词在特定目标下,处于向量空间中的位置。
将词嵌入的思路推广到其它的离散特征处理中,我们可以用同样的方法将各种类别特征如“用户性别”、“城市”、“日期”嵌入到稠密的向量空间中。经过这样处理之后,自然就解决了原本 FM 遇到的特征稀疏问题。
高阶交叉特征
在广告场景下,特征交叉的组合与点击率是有显著相关的,例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女性”,“球类运动配件”的商品与“男性”,“电影票”的商品与“电影”品类偏好等。因此,引入特征的组合是非常有意义的。看到这种需要,我们很容易就能想到 SVM 里面的多项式核函数,FM 就是在多项式核的基础上,优化了稀疏问题以及计算复杂度的产物。
为什么要Embedding? 在web-scale的推荐系统比如CTR预估中,输入的大部分特征都是类别型特征,通常的处理办法就是one-hot,但是one-hot之后输入特征维度非常高非常系数。所以有了Embedding来大大的降低输入的维度,就是把这些binary features转换成dense vectors with real values。
Embedding操作其实就是用一个矩阵和one-hot之后的输入相乘,也可以看成是一次查询(lookup)。这个Embedding矩阵跟网络中的其他参数是一样的,是需要随着网络一起学习的。
为什么要Stacking? 处理完了类别型特征,还有连续型特征没有处理那。所以我们把连续型特征规范化之后,和嵌入向量stacking到一起,就得到了原始的输入:
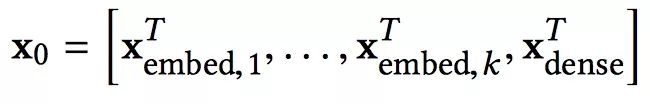
文中对原始特征做如下处理:1) 对sparse特征进行embedding,对于multi-hot的sparse特征,embedding之后再做一个简单的average pooling;2) 对dense特征归一化,然后和embedding特征拼接,作为随后Cross层与Deep层的共同输入,即:
Cross Layer
Cross的目的是以一种显示、可控且高效的方式,自动构造有限高阶交叉特征,我们会对这些特点进行解读。Cross结构如上图1左侧所示,其中第 层输出为:
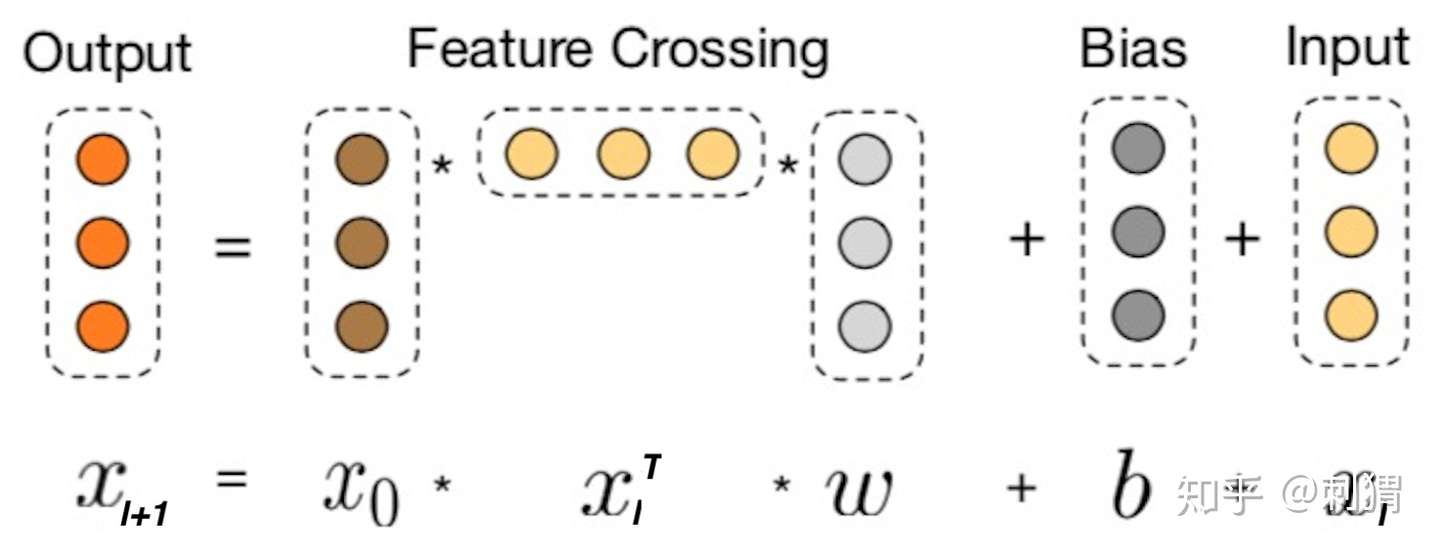
其中
Cross Layer 设计的巧妙之处全部体现在上面的计算公式中,我们先看一些明显的细节:1) 每层的神经元个数都相同,都等于输入 的维度
,也即每层的输入输出维度都是相等的;2) 受残差网络(Residual Network)结构启发,每层的函数
拟合的是
的残差,残差网络有很多优点,其中一点是处理梯度消失的问题,使网络可以“更深”.
那么为什么这样设计呢?Cross究竟做了什么?对此论文中给出了定理3.1以及相关证明,但定理与证明过程都比较晦涩,为了直观清晰地讲解清楚,我们直接看一个具体的例子:假设Cross有2层, 为便于讨论令各层 ,则
最后得到 包含了其从一阶到三阶的所有可能叉乘组合。现在大家应该可以理解cross layer计算公式的用心良苦了,上面这个例子也可以帮助我们更深入地理解Cross的设计:
有限高阶:叉乘阶数由网络深度决定,深度
阶的叉乘
自动叉乘:Cross输出包含了原始特征从一阶(即本身)到
阶的所有叉乘组合,而模型参数量仅仅随输入维度成线性增长:
参数共享:不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重(指数数量级), 通过参数共享,Cross有效降低了参数量。此外,参数共享还使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中
这个叉乘特征没有出现 ,对应权重肯定是零,而参数共享则不会,类似地,数据集中的一些噪声可以由大部分正常样本来纠正权重参数的学习
def cross_layer(x0, x, name):
with tf.variable_scope(name):
input_dim = x0.get_shape().as_list()[1]
w = tf.get_variable("weight", [input_dim],
initializer=tf.truncated_normal_initializer(stddev=0.01))
b = tf.get_variable("bias", [input_dim],
initializer=tf.truncated_normal_initializer(stddev=0.01))
xb = tf.tensordot(tf.reshape(x, [-1, 1, input_dim]), w, 1)
return x0 * xb + b + x前面介绍过,文中将dense特征和embedding特征拼接后作为Cross层和Deep层的共同输入。这对于Deep层是合理的,但我们知道人工交叉特征基本是对原始sparse特征进行叉乘,那为何不直接用原始sparse特征作为Cross的输入呢?联系这里介绍的Cross设计,每层layer的节点数都与Cross的输入维度一致的,直接使用大规模高维的sparse特征作为输入,会导致极大地增加Cross的参数量。当然,可以畅想一下,其实直接拿原始sparse特征喂给Cross层,才是论文真正宣称的“省去人工叉乘”的更完美实现,但是现实条件不太允许。所以将高维sparse特征转化为低维的embedding,再喂给Cross,实则是一种trade-off的可行选择。
- 联合训练
模型的Deep 部分如图1右侧部分所示,DCN拼接Cross 和Deep的输出,采用logistic loss作为损失函数,进行联合训练,这些细节与Wide & Deep几乎是一致的,在这里不再展开论述。另外,文中也在目标函数中加入L2正则防止过拟合。
- 模型分析
设初始输入 维度为
,Deep和Cross层数分别为
和
,为便于分析,设Deep每层神经元个数为
,则两部分的参数量为:
Cross:
Deep:
可以看到Cross的参数量随 增大仅呈“线性增长”!相比于Deep部分,对整体模型的复杂度影响不大,这得益于Cross的特殊网络设计,对于模型在业界落地并实际上线来说,这是一个相当诱人的特点。
Deep Network
这一部分没什么特别的,就是一个前向传播的全连接神经网络,我们可以计算一下参数的数量来估计下复杂度。假设输入x0维度为d,一共有Lc层神经网络,每一层的神经元个数都是m个。那么总的参数或者复杂度为:

Combination Layer
Combination Layer把Cross Network和Deep Network的输出拼接起来,然后经过一个加权求和后得到logits,然后经过sigmoid函数得到最终的预测概率。形式化如下:
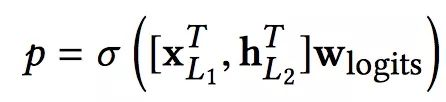
p是最终的预测概率;XL1是d维的,表示Cross Network的最终输出;hL2是m维的,表示Deep Network的最终输出;Wlogits是Combination Layer的权重;最后经过sigmoid函数,得到最终预测概率。
损失函数使用带正则项的log loss,形式化如下:
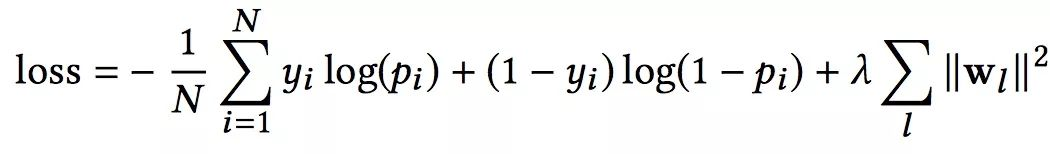
另外,针对Cross Network和Deep Network,DCN是一起训练的,这样网络可以知道另外一个网络的存在。
泛化FM
跟FM一样,DCN同样也是基于参数共享机制的,参数共享不仅仅使得模型更加高效而且使得模型可以泛化到之前没有出现过的特征组合,并且对噪声的抵抗性更加强。
FM是一个非常浅的结构,并且限制在表达二阶组合特征上,DeepCrossNetwork(DCN)把这种参数共享的思想从一层扩展到多层,并且可以学习高阶的特征组合。但是和FM的高阶版本的变体不同,DCN的参数随着输入维度的增长是线性增长的。