Word Embedding && Word2Vec
什么是Word Representation?
对人来说一个单词就是一个单词,但是对计算机来说却不是这样,那么计算机是如何处理单词或者文本的呢?最简单最直观的做法就是把单词(word)按照某种规则表达成一个向量(vector),这就是Word Representation。
什么是one-hot encoding?
比如:假设我们有这样的两个文本:
- D1: I like green
- D2: I like red
那么针对这两个文本所组成的语料库而言,我们会得到如下所示的字典:[green, I, like, red],那么单词”I”的one-hot encoding就是[0100],单词”like”则是[0010]。
优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用。
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
Dristributed representation
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。
什么是Word Embedding?
要理解这个概念,先理解什么是Emdedding?Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。 那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。 通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,该表达就是word representation。
Embedding能够用低维向量对物体进行编码还能保留其含义的特点非常适合深度学习。在传统机器学习模型构建过程中,我们使用one hot encoding对离散特征,特别是id类特征进行编码,但由于one hot encoding的维度等于物体的总数,比如阿里的商品one hot encoding的维度就至少是千万量级的。这样的编码方式对于商品来说是极端稀疏的,甚至用multi hot encoding对用户浏览历史的编码也会是一个非常稀疏的向量。而深度学习的特点以及工程方面的原因使其不利于稀疏特征向量的处理。因此如果能把物体编码为一个低维稠密向量再喂给 DNN,自然是一个高效的基本操作。
有哪些类型的Word Embeddings?
目前主要分为两类:
- Frequency based Embedding
- Prediction based Embedding
Frequency based Embedding就是基于词频统计的映射方式,主要有以下三种:
Count Vector 这种就是最简单,最基本的词频统计算法:比如我们有N个文本(document),我们统计出所有文本中不同单词的数量,结果组成一个矩阵。那么每一列就是一个向量,表示这个单词在不同的文档中出现的次数。
TF-IDF Vector
Co-Occurrence Vector
这个比较有意思,中文直译过来就是协同出现向量。在解释这个概念之前,我们先定义两个变量:
- Co-occurrence 协同出现指的是两个单词w1和w2在一个Context Window范围内共同出现的次数
- Context Window 指的是某个单词w的上下文范围的大小,也就是前后多少个单词以内的才算是上下文?比如一个Context Window Size = 2的示意图如下:

比如我们有如下的语料库:
He is not lazy. He is intelligent. He is smart.
我们假设Context Window=2,那么我们就可以得到如下的co-occurrence matrix:
 这个方法比之前两个都要进步一点,为什么呢? 因为它不再认为单词是独立的,而考虑了这个单词所在附近的上下文,这是一个很大的突破。 如果两个单词经常出现在同一个上下文中,那么很可能他们有相同的含义。比如vodka和brandy可能经常出现在wine的上下文里,那么在这两个单词相对于wine的co-occurrence就应该是相近的,于是我们就可以认为这两个单词的含义是相近的。
这个方法比之前两个都要进步一点,为什么呢? 因为它不再认为单词是独立的,而考虑了这个单词所在附近的上下文,这是一个很大的突破。 如果两个单词经常出现在同一个上下文中,那么很可能他们有相同的含义。比如vodka和brandy可能经常出现在wine的上下文里,那么在这两个单词相对于wine的co-occurrence就应该是相近的,于是我们就可以认为这两个单词的含义是相近的。
language modelling
Language models generally try to compute the probability of a word wtwt given its n−1n−1 previous words, i.e. p(wt|wt−1,⋯wt−n+1)p(wt|wt−1,⋯wt−n+1). By applying the chain rule together with the Markov assumption, we can approximate the probability of a whole sentence or document by the product of the probabilities of each word given its nn previous words:
$p(w_1 , \cdots , w_T) = \prod\limits_i p(w_i : | : w_{i-1} , \cdots , w_{i-n+1})$
In n-gram based language models, we can calculate a word's probability based on the frequencies of its constituent n-grams:
$p(w_t : | : w_{t-1} , \cdots , w_{t-n+1}) = \dfrac{count(w_{t-n+1}, \cdots , w_{t-1},w_t)}{count({w_{t-n+1}, \cdots , w_{t-1} })}$
Setting n=2 yields bigram probabilities, while n=5 together with Kneser-Ney smoothing leads to smoothed 5-gram models that have been found to be a strong baseline for language modelling.
In neural networks, we achieve the same objective using the well-known softmax layer:
$p(w_t : | : w_{t-1} , \cdots , w_{t-n+1}) = \dfrac{\text{exp}({h^\top v'{w_t} })}{\sum{w_i \in V} \text{exp}({h^\top v'_{w_i} })}$
The inner product h⊤v′wth⊤vwt′ computes the (unnormalized) log-probability of word wtwt, which we normalize by the sum of the log-probabilities of all words in VV. hh is the output vector of the penultimate network layer (the hidden layer in the feed-forward network in Figure 1), while v′wvw′ is the output embedding of word ww, i.e. its representation in the weight matrix of the softmax layer. Note that even though v′wvw′ represents the word ww, it is learned separately from the input word embedding vwvw, as the multiplications both vectors are involved in differ (vwvw is multiplied with an index vector, v′wvw′ with hh).
Word2vec
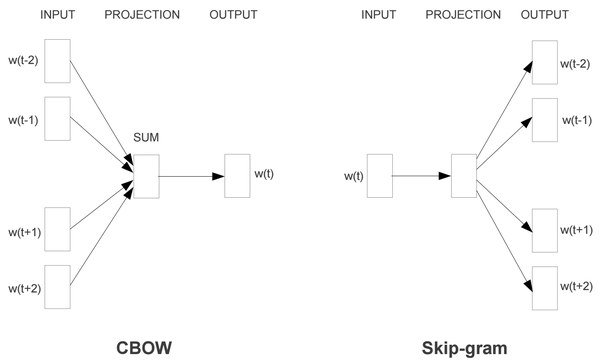
上面介绍的三种Word Embedding方法都是确定性(deterministic)的方法,而接下来介绍一种非确定性的基于神经网络的预测模型 word2vec。既然我们要训练一个对word的语义表达,那么训练样本显然是一个句子的集合。假设其中一个长度为T的句子为 。这时我们假定每个词都跟其相邻的词的关系最密切,换句话说每个词都是由相邻的词决定的(CBOW模型的动机),或者每个词都决定了相邻的词(Skip-gram模型的动机)。
如下图,CBOW的输入是 周边的词,预测的输出是
,而Skip-gram则反之,经验上讲Skip-gram的效果好一点,所以本文从Skip-gram模型出发讲解模型细节。
Skip-gram
如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
COBW(Continuous Bag of words)
而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
理解COBW
接下来我们以CBOW模型为例介绍下word2vec是如何实现词嵌入和语言模型的。为了产生模型的正样本,我们选一个长度为2c+1(目标词前后各选c个词)的滑动窗口,从句子左边滑倒右边,每滑一次,窗口中的词就形成了我们的一个正样本。
有了训练样本之后我们就可以着手定义优化目标了,既然每个词 都决定了相邻词
,基于极大似然,我们希望所有样本的条件概率
之积最大,这里我们使用log probability。我们的目标函数有了:
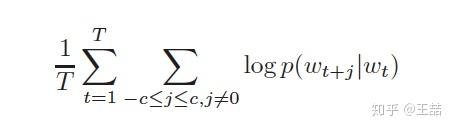
接下来的问题是怎么定义 ,作为一个多分类问题,最简单最直接的方法当然是直接用softmax函数,我们又希望用向量
表示每个词w,用词之间的距离
表示语义的接近程度,那么我们的条件概率的定义就可以很直观的写出。
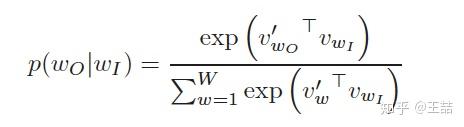
看到上面的条件概率公式,很多同学可能会习惯性的忽略一个事实,就是
我们用 去预测
,但其实这二者的向量表达并不在一个向量空间内。
就像上面的条件概率公式写的一样, 和
分别是词w的输出向量表达和输入向量表达。那什么是输入向量表达和输出向量表达呢?我们画一个word2vec的神经网络架构图就明白了。
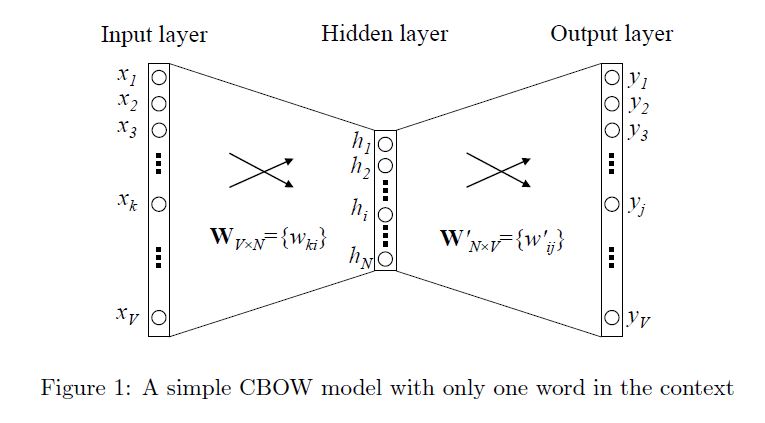
根据 的定义,我们可以把两个vector的乘积再套上一个softmax的形式转换成上面的神经网络架构(需要非常注意的一点事hidden layer的激活函数,大家要思考一下,到底是sigmoid函数还是普通的线性函数,为什么?)。在训练过程中我们就可以通过梯度下降的方式求解模型参数了。那么上文所说的输入向量表达就是input layer到hidden layer的权重矩阵
,而输出向量表达就是hidden layer到output layer的权重矩阵
。
那么到底什么是我们通常意义上所说的词向量 呢?
其实就是我们上面所说的输入向量矩阵 中每一行对应的权重向量。于是这个权重矩阵自然转换成了word2vec的lookup table。

多个单词的CBOW模型结构如下:  其中,V 表示词库的大小;输入向量 $ x1,x2,…,xV$的大小为 1×V,它是这个 word 的 one-hot encoding;神经元$h1,h2,…,hN$ 表示Hidden Layer,大小为1×N;输出向量$y1,y2,…,yV $表示的是一个概率分布向量,大小和输入向量一致。
其中,V 表示词库的大小;输入向量 $ x1,x2,…,xV$的大小为 1×V,它是这个 word 的 one-hot encoding;神经元$h1,h2,…,hN$ 表示Hidden Layer,大小为1×N;输出向量$y1,y2,…,yV $表示的是一个概率分布向量,大小和输入向量一致。
这个结构是如何实现词嵌入和语言模型的呢? 要解答这个问题,首先要充分理解输出层的概率分布向量到底是什么?怎么理解?我们以多个单词的CBOW模型为例,CBOW的任务就是给定了一个长度为C个单词的上下文(单词的顺序无关)去预测最有可能的空缺单词。我们通过神经网络训练之后得到的预测结果是一个V维的向量,而这个向量代表的是词库里的每一个单词是空缺单词的概率。这样也就实现了语言模型。而神经网络中的Hidden Layer就是我们想要的词嵌入,它不仅得到了单词的语义特性,还把单词从V维空间映射到了N维,因为词库的大小V往往很大,所以这样做也实现了降维处理。因此,我们也可以说词嵌入是word2vec训练语言模型的副产物。
如何理解CBOW的词嵌入? 对于Hidden Layer的直观解释就是这个单词本身被解释成大小为N的向量/特征(features),也就说单词本身也有了属性,而这些属性就是隐藏层的权重,假想图(因为没人知道究竟被解释成了那些特征)如下:

COBW可视化
下面我们借助一个在线的visualization工具wevi: word embedding visual inspector来进一步理解,我们首先看一下它的training data:
drink,juice|apple;
eat,apple|orange;
drink,juice|rice;…
其中,竖线之前的表示input,每个input的单词用逗号分隔,之后是output。比如对于如下这组训练数据而言:
drink,juice|apple
它在神经网络中的表现就是这样的:  看完一个training data就觉得这个东西很简单了,本质上就是一个简单的神经网络嘛,其实完全可以不用理解hidden layer所包含的特殊意义,直接把它理解成一个端对端(end-to-end)的系统更好理解,创新的地方就是训练单词时结合了它的上下文。
看完一个training data就觉得这个东西很简单了,本质上就是一个简单的神经网络嘛,其实完全可以不用理解hidden layer所包含的特殊意义,直接把它理解成一个端对端(end-to-end)的系统更好理解,创新的地方就是训练单词时结合了它的上下文。
Skip-gram模型
Skip-Gram模型的基础形式非常简单,为了更清楚地解释模型,我们先从最一般的基础模型来看Word2Vec(下文中所有的Word2Vec都是指Skip-Gram模型)。
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。
Skip-gram模型的计算过程跟COBW类似,只不过是一个相反的过程,它的结构如下: 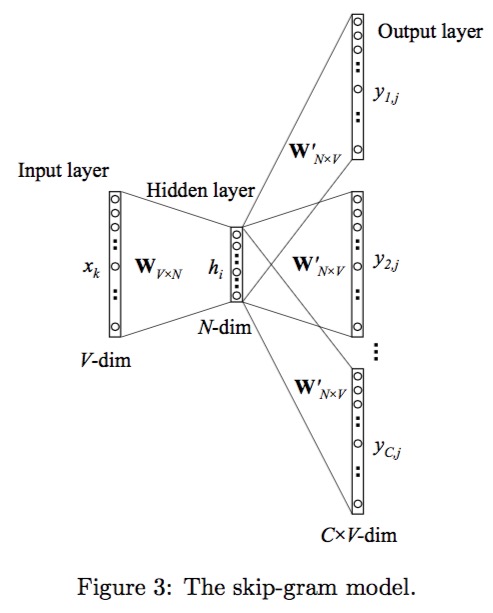
Skip-gram可视化
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。
- 首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
- 有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置
,那么我们最终获得窗口中的词(包括input word在内)就是['The', 'dog','barked', 'at']。
。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当
时,我们将会得到两组 (input word, output word) 形式的训练数据,即 ('dog', 'barked'),('dog', 'the')。
- 神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。这句话有点绕,我们来看个栗子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 ('dog', 'barked') 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率大小。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。 我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。
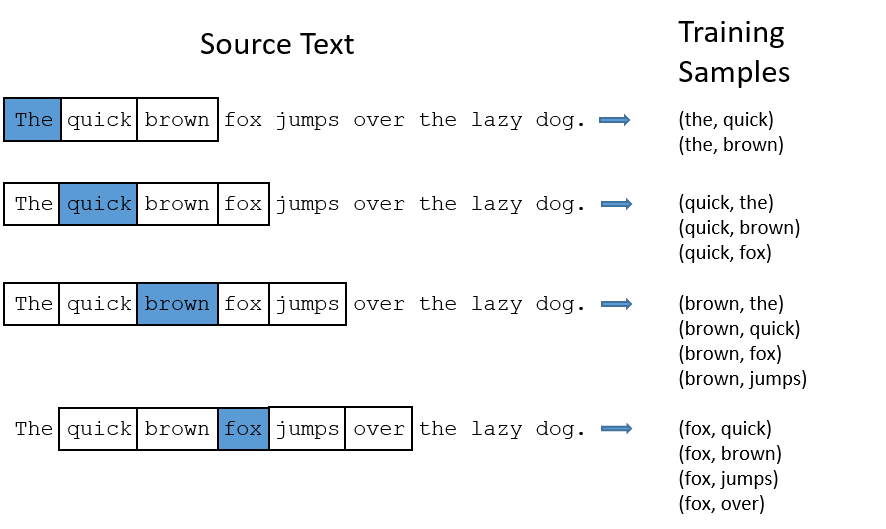
我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
sample training data:
apple|drink,juice;
orange|eat,apple;
rice|drink,juice;…
比如对于如下这组数据而言:
apple|drink,juice
它在神经网络中的表现就是这样的: 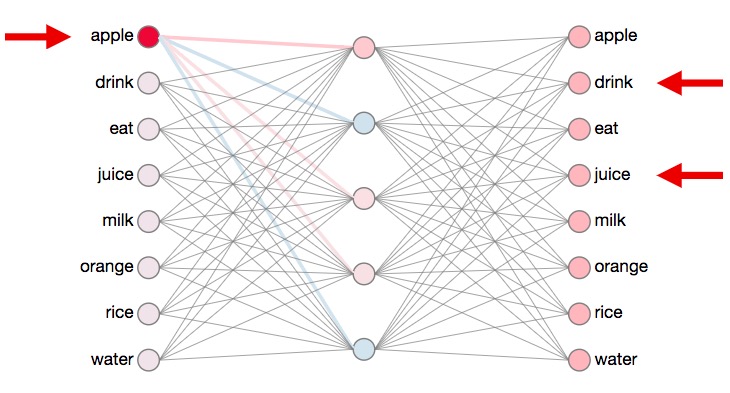
总结
其实word2vec和Co-Occurrence Vector的思想是很相似的,都是基于一个统计学上的假设:经常在同一个上下文出现的单词是相似的。只是他们的实现方式是不一样的,前者是采用词频统计,降维,矩阵分解等确定性技术;而后者则采用了神经网络进行不确定预测,它的提出主要是采用神经网络之后计算复杂度和最终效果都比之前的模型要好。所以那篇文章的标题才叫:Efficient Estimation of Word Representations in Vector Space。 这项技术可以用来估算两个单词之间的相似度,它在自然语言处理(NLP),搜索以及机器翻译(machine translation)等领域有着广泛的应用。比如你在用Google搜索“hotel”时,它不仅仅会返回给你包含hotel的网页,也会返回一些包含“motel,airbnb”之类的网页。还有一个是在搜索框输入一个单词之后,会自动预测后面可能出现的单词。
参考资料
1 . Mikolov 两篇原论文:
『Distributed Representations of Sentences and Documents』
贡献:在前人基础上提出更精简的语言模型(language model)框架并用于生成词向量,这个框架就是 Word2vec
『Efficient estimation of word representations in vector space』
贡献:专门讲训练 Word2vec 中的两个trick:hierarchical softmax 和 negative sampling
优点:Word2vec 开山之作,两篇论文均值得一读
缺点:只见树木,不见森林和树叶,读完不得要义。 这里『森林』指 word2vec 模型的理论基础——即 以神经网络形式表示的语言模型 『树叶』指具体的神经网络形式、理论推导、hierarchical softmax 的实现细节等等
- 北漂浪子的博客:『深度学习word2vec 笔记之基础篇』
优点:非常系统,结合源码剖析,语言平实易懂
缺点:太啰嗦,有点抓不住精髓
- Yoav Goldberg 的论文:『word2vec Explained- Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method』
优点:对 negative-sampling 的公式推导非常完备
缺点:不够全面,而且都是公式,没有图示,略显干枯
- Xin Rong 的论文:『word2vec Parameter Learning Explained』:
重点推荐! 理论完备由浅入深非常好懂,且直击要害,既有 high-level 的 intuition 的解释,也有细节的推导过程
- 来斯惟的博士论文『基于神经网络的词和文档语义向量表示方法研究』以及他的博客(网名:licstar) 可以作为更深入全面的扩展阅读,这里不仅仅有 word2vec,而是把词嵌入的所有主流方法通通梳理了一遍
- 几位大牛在知乎的回答:『word2vec 相比之前的 Word Embedding 方法好在什么地方?』 刘知远、邱锡鹏、李韶华等知名学者从不同角度发表对 Word2vec 的看法,非常值得一看
- Sebastian 的博客:『On word embeddings - Part 2: Approximating the Softmax』 详细讲解了 softmax 的近似方法,Word2vec 的 hierarchical softmax 只是其中一种