Ascend Pytorch 适配方案
文档总览
| 文档 | 内容介绍 | 关键资源获取 |
|---|---|---|
| 产品概述 | 快速了解Ascend Extension for PyTorch的架构及关键功能特性。 | 《产品概述》 |
| 配置与安装 | 详细介绍不同昇腾硬件产品形态的安装方案、环境搭建流程,以及卸载、其他常用操作等。 | 《Ascend Extension for PyTorch 配置与安装》 |
| 快速体验 | 以一个简单的模型迁移样例,采用了最简单的自动迁移方法,帮助用户快速体验其他平台的模型脚本迁移到昇腾NPU上的流程,并通过修改脚本代码,使其可以迁移到昇腾NPU上进行训练。 | 《快速体验》 |
| 模型开发 | 包含了大模型的迁移及调优、精度问题定位、性能问题解决等指导,并提供了常见模型案例库。训练模型迁移调优主要目标是引导具有一定PyTorch模型训练基础的读者,了解如何将原本在其他平台(例如GPU)上训练的模型迁移到昇腾平台(NPU)。主要介绍多种类、全流程的迁移过程:无论是针对小规模模型还是大型模型,都提供了详尽的指导。重点关注如何有效地将PyTorch训练模型进行迁移,在昇腾平台上进行训练功能。精度调试介绍了大模型训练过程中常见的问题及其调试方法,帮助用户将问题消除在训练开始之前,以及缩短模型精度问题定位的时间。性能调优主要介绍NPU性能的拆解和分析以及优化方法。模型案例介绍了多模态模型、LLM大模型以及自动驾驶模型的迁移案例。 | 《PyTorch 训练模型迁移调优指南》 |
| 套件与三方库 | 包含了套件与三方库支持清单,提供了基于TorchAir的PyTorch图模式使用和MindSpeed迁移开发的指导。套件与三方库支持清单主要介绍昇腾设备支持的模型套件列表、第三方库原生支持和适配清单。TorchAir主要介绍将PyTorch的FX图转换为GE计算图,并提供了GE计算图的编译与执行接口。MindSpeedMindSpeed是针对华为昇腾设备的大模型加速库。昇腾提供该加速库,使能客户大模型业务快速迁移至昇腾设备,并且支持昇腾专有算法,确保开箱可用。 | 《套件与三方库支持清单》《PyTorch 图模式使用指南(TorchAir)》《MindSpeed 迁移开发指南》 |
| API参考 | 主要介绍原生PyTorch框架2.3.1/2.2.0/2.1.0/1.11.0的API接口支持情况与限制说明以及Ascend Extension for PyTorch自定义API的接口说明、功能描述、参数说明与使用示例。 | 《API 参考》 |
| 环境变量 | 包含了开发者基于CANN及Ascend Extension for PyTorch构建AI应用和训练执行中可使用的环境变量。 | 《CANN 环境变量参考》中的“Ascend Extension for PyTorch”章节 |
适配方案简介
昇腾是当前国产芯片中唯一能够进行大规模分布式训练集群部署的厂商,其适配了主流的深度学习训练框架,包括自研的Mindspore和适配的TensorFlow和Pytorch。其中PyTorch因其易用性、灵活性和强大的社区支持而受到许多深度学习研究者和开发者的喜爱。昇腾芯片对Pytorch框架的适配能够快速帮助它共享和扩大Pytorch强大的生态,对其未来的发展至关重要。
对Pytorch适配有两个主要思路:
- 将Pytorch的接口转接到Mindspore对应的接口上;实际上就是将Pytorch的前端代码的计算逻辑映射到Mindspore框架上去,然后由Mindspore去执行;这种方案的问题在于Pytorch和Mindspore的内在逻辑无法相通,比如Pytorch的动态图和Mindspore的静态图直接就可能存在直接矛盾;举一个例子,Mindspore虽然同时支持动态图和静态图,但是一份相同的代码在动态图下可以正常运行,但是在静态图下就会报错。
- 利用插件来对原生Pytorch进行适配,针对原生扩展逻辑进行逐一适配,API基本跟Pytorch一致,譬如除开昇腾芯片不支持的fp64数据格式,其它基本都能满足。简单来理解,就是从算子层面对Pytorch的计算后端进行替换,采用昇腾开发的算子来替换GPU算子。这种方案能够充分的利用原生Pytorch框架的优势,也是是Pytorch适配的目标。
插件适配方案
侵入式适配
早期的Ascend Pytorch采用侵入式适配,即直接修改原生Pytorch代码,带来的问题非常明显,比如:
- 质量难以控制,且项目测试工程量巨大;
- 版本升级困难,每个新版版都需要重新适配;
采用插件化开发的方式,上面的问题就能够得到解决。
Ascend Extension for PyTorch插件
Ascend Extension for PyTorch 插件是基于昇腾的深度学习适配框架,使昇腾NPU可以支持PyTorch框架,为PyTorch框架的使用者提供昇腾AI处理器的超强算力。
项目源码地址:
方案特性
当前阶段,本产品对PyTorch框架与昇腾AI处理器进行了在线对接适配。
昇腾AI处理器的加速实现方式是以算子为粒度进行调用(OP-based),即通过Ascend Computing Language(AscendCL)调用一个或几个亲和算子组合的形式,代替原有的算子实现方式。PyTorch适配插件架构图如下所示。

图1 PyTorch适配插件架构图
该在线对接适配方案的特点包含:
- 最大限度的继承PyTorch框架动态图的特性。
- 最大限度的继承原生PyTorch的开发方式,可以使用户在将模型移植到昇腾AI处理器设备进行训练时,在开发方式和代码重用方面做到最小的改动。
- 最大限度的继承PyTorch原生的体系结构,保留框架本身出色的特性,比如自动微分、动态分发、Debug、Profiling、Storage共享机制以及设备侧的动态内存管理等。
- 扩展性好。在打通流程的通路之上,对于新增的网络类型或结构,只需涉及相关计算类算子的开发和实现。框架类算子,反向图建立和实现机制等结构可保持复用。
- 与原生PyTorch的使用方式和风格保持一致。用户在使用在线对接方案时,只需在Python侧和Device相关操作中,指定Device为昇腾AI处理器,即可完成用昇腾AI处理器在PyTorch对网络的开发、训练以及调试,用户无需进一步关注昇腾AI处理器具体的底层细节。这样可以确保用户的修改最小化,迁移成本较低。
核心机制-dispatch
简单而言,就是根据API调用时,输入的数据类型来决定后端调用的API类型。比如CPU和GPU的API是不一样的,可以自动根据传入的tensor类型来自动选择API。
具体来看,对于每一个前端的算子,dispatcher 会维护一个函数指针表,为每个dispatch key提供对应的视线。这个表中有针对不同后端(CPU,GPU,XLA)的dispatch条目,也有想autograd和tracing这样的高抽象层级概念的条目。dispatcher根据输入的tensor和其他东西计算出一个dispatch key,然后跳转到函数指针表所指向的函数。
所以,对于昇腾处理器而言,实现Adapter主要就是要讲用昇腾实现的算子注册到dispatcher上面,即可复用pytorch的dispatch机制完成算子分布。
示例-单算子调用流程
- 用户在前端调用算子,比如可调用nn.Module,nn.Funtional,Tensor对象上的函数;
- pybind11根据注册绑定的映射规则,调用后端C++方法;
- 后端C++接口根据输入参数来选取所需调用的算子类型(dispatch机制),比如是调用CPU实现的算子还是GPU实现的算子(注意:此处只要注册NPU实现的算子,便可调用昇腾处理器的计算能力;
- 调用相应算子,返回结果;
PyTorch Adapter的逻辑架构图
在线适配方案:模型执行,训练等主要功能流程有Pytorch框架提供,用户界面API保持不变,将Davinci设备和计算库作为扩展资源注册到PyTorch框架中。
- 优点:
- 继承PyTorch动态图特性
- 继承原生PyTorch使用方式,移植的时候,在开发方式和代码复用方便做到最小的改动;
- 继承Pytorch的原生体系结构,保留框架本身出色的特性,比如自动微分,动态分发,Debug,Profiling,Storage共享机制等;
- 扩展性:对于新增网络类型或结构,只需增加涉及的算子开发和实现。框架类算子,反向图建立和实现机制等结构可保持复用;
配置与安装
快速安装 Ascend CANN Toolkit
在昇腾 NPU 设备上安装 Pytorch 时,需要安装 Ascend CANN Toolkit 与 Kernels,安装方法请参考上面的安装教程或使用以下命令:
# 请替换 URL 为 CANN 版本和设备型号对应的 URL
# 安装 CANN Toolkit
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run
bash Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run --install
# 安装 CANN Kernels
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run
bash Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run --install
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh| 依赖项 | 至少 | 推荐 |
|---|---|---|
| CANN | 8.0.RC1 | 8.0.RC1 |
| torch | 2.1.0 | 2.1.0 |
| torch-npu | 2.1.0 | 2.1.0.post3 |
| deepspeed | 0.13.2 | 0.13.2 |
请使用 ASCEND_RT_VISIBLE_DEVICES 而非 CUDA_VISIBLE_DEVICES 来指定运算设备。
快速安装 Ascend Pytorch
# 下载PyTorch安装包
wget https://download.pytorch.org/whl/cpu/torch-2.2.0%2Bcpu-cp310-cp310-linux_x86_64.whl
# 下载torch_npu插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2-pytorch2.2.0/torch_npu-2.2.0.post2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
# 安装命令
pip3 install torch-2.2.0+cpu-cp310-cp310-linux_x86_64.whl
pip3 install torch_npu-2.2.0.post2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl验证是否成功安装
验证是否安装成功,可执行如下命令:
python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"显示如下类似信息证明PyTorch框架与插件安装成功。
tensor([[-0.6066, 6.3385, 0.0379, 3.3356],
[ 2.9243, 3.3134, -1.5465, 0.1916],
[-2.1807, 0.2008, -1.1431, 2.1523]], device='npu:0')安装说明
基于昇腾训练设,如何昇腾NPU(Neural-Network Processing Unit,神经网络处理器单元)驱动固件、CANN(Compute Architecture for Neural Networks,AI异构计算架构)软件的安装,各软件说明如表1所示。
表1 昇腾软件介绍
| 软件类型 | 软件介绍 |
|---|---|
| 昇腾NPU固件 | 固件包含昇腾AI处理器自带的OS 、电源器件和功耗管理器件控制软件,分别用于后续加载到AI处理器的模型计算、芯片启动控制和功耗控制。 |
| 昇腾NPU驱动 | 部署在昇腾服务器,管理查询昇腾AI处理器,同时为上层CANN软件提供芯片控制、资源分配等接口。 |
| CANN | 部署在昇腾服务器,包含Runtime、算子库、图引擎、媒体数据处理等组件,通过AscendCL(Ascend Computing Language,昇腾计算语言)对外提供Device管理、Context管理、Stream管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等API,帮助开发者实现在昇腾软硬件平台上开发和运行AI业务。CANN软件按照功能主要分为Toolkit(开发套件)、Kernels(二进制算子包)、NNAE(深度学习引擎)、NNRT(离线推理引擎)、NNAL(加速库)、TFPlugin(TensorFlow框架插件)几种软件包,各软件包支持功能范围如下:Toolkit:支持训练和推理业务、模型转换、算子/应用/模型开发和编译。NNAE:支持训练和推理业务。NNRT:仅支持离线推理。TFPlugin:用于运行训练业务时和TensorFlow框架进行对接,帮助TensorFlow框架调用底层CANN接口运行训练业务。Kernels:依赖Toolkit、NNRT或NNAE软件包,可以节省算子编译时间。在包含动态shape网络或单算子API(例如aclnn类API)场景下需安装二进制算子包。NNAL:依赖Toolkit,包含面向大模型领域的ATB(Ascend Transformer Boost)加速库,可以提升大模型训练和推理性能。 |
用户需完成硬件、OS、昇腾NPU驱动固件以及CANN软件的安装,CANN软件使用Toolkit(开发套件),深度学习框架使用PyTorch框架。
安装前必读
为使用PyTorch框架的开发者提供昇腾AI处理器的超强算力,昇腾开发Ascend Extension for PyTorch(即torch_npu插件)用于适配PyTorch框架,本章节指导用户在昇腾环境安装PyTorch框架和torch_npu插件。
前提条件
安装配套版本的NPU驱动固件、CANN软件(Toolkit以及二进制算子包)并配置CANN环境变量,具体请参考
《CANN 软件安装指南》。
CANN软件提供进程级环境变量设置脚本,供用户在进程中引用,以自动完成环境变量设置。用户进程结束后自动失效。示例如下(以root用户默认安装路径为例):
shell. /usr/local/Ascend/ascend-toolkit/set_env.sh用户也可以通过修改~/.bashrc文件方式设置永久环境变量,操作如下:
- 以运行用户在任意目录下执行vi ~/.bashrc命令,打开.bashrc文件,在文件最后一行后面添加上述内容。
- 执行:wq!命令保存文件并退出。
- 执行source ~/.bashrc命令使其立即生效。
安装对应框架版本的torchvision,PyTorch 1.11.0版本需安装0.12.0版本,PyTorch 2.1.0版本需安装0.16.0版本,PyTorch 2.2.0版本需安装0.17.0版本,PyTorch 2.3.1版本需安装0.18.0版本。
执行如下命令安装torchvision,以0.12.0版本为例:
shellpip3 install torchvision==0.12.0通过源码编译安装torch_npu插件时,安装如下环境依赖。
执行如下命令安装。如果使用非root用户安装,需要在命令后加--user,例如:pip3 install pyyaml --user。
shellpip3 install pyyaml pip3 install wheel pip3 install setuptools
安装PyTorch框架
获取安装命令
# 下载软件包
wget https://download.pytorch.org/whl/cpu/torch-2.2.0%2Bcpu-cp310-cp310-linux_x86_64.whl
# 安装命令
pip3 install torch-2.2.0+cpu-cp310-cp310-linux_x86_64.whl安装torch_npu插件
torch_npu插件有两种安装方式:
- 快速安装:通过wheel格式的二进制软件包直接安装。
- 源码编译安装:用户可以选择对应的分支自行编译torch_npu。编译安装适用于进行算子适配开发、CANN版本与PyTorch兼容适配场景下使用。
说明
- 源码安装时,支持安装Ascend PyTorch OpPlugin项目开发的NPU PyTorch算子插件,提供便捷的NPU算子库调用能力。OpPlugin算子插件与CANN版本耦合,源码编译PyTorch时指定OpPlugin版本,可以实现PyTorch在版本不匹配的CANN上运行,实现灵活的版本兼容性。
获取安装命令
# 下载插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2-pytorch2.2.0/torch_npu-2.2.0.post2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
# 安装命令
pip3 install torch_npu-2.2.0.post2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whlPytorch模型迁移
概述
什么是模型迁移
将原本设计用于GPU或其他三方平台的深度学习模型训练代码,经过模型代码修改等适配操作,来适应NPU的架构和编程,让模型能在NPU上进行高性能运行。
为什么要做模型迁移
在将模型从其他三方平台迁移到NPU时,由于硬件架构和库的不同,涉及到一系列底层到上层的适配操作。以GPU为例,模型迁移至NPU需要适配的原因可分为三方面:
硬件特性和性能特点差异
由于NPU和GPU的硬件特性和性能特点不同,模型在NPU上可能需要进一步的性能调试和优化,以充分发挥NPU的潜力。
计算架构差异
CUDA(Compute Unified Device Architecture)+ CuDNN是NVIDIA GPU的并行计算框架,而CANN(Compute Architecture for Neural Networks)是华为NPU的异构计算架构。
深度学习框架差异
为了支持NPU硬件,需要对PyTorch框架进行适配:包括适配张量运算、自动微分等功能,以便在NPU上高效执行。PyTorch正在原生支持NPU,以提供给用户更好的模型体验,实现迁移修改最小化。
迁移总体思路
通用模型迁移适配方法,可以分为四个阶段:迁移分析、迁移适配、精度调试与性能调优,如图所示。

图1 训练模型迁移总体流程图
迁移适配流程
迁移适配流程总体可分为模型脚本迁移、环境变量和脚本配置和关键特性适配三部分,主要包含以下工作:
- 模型脚本迁移:介绍如何把三方平台上的PyTorch模型代码映射到昇腾设备上。推荐使用自动迁移,通过导入一键迁移库的形式,将三方平台上的代码映射为昇腾设备代码。
- 环境变量和脚本配置:介绍在昇腾设备上运行PyTorch模型代码时,必须的适配操作,包括环境变量配置和模型脚本与启动脚本配置。
- 关键特性适配:介绍在昇腾设备上运行PyTorch模型代码时,可选的适配操作。用户需要查看特性是否适用于当前训练场景与设备,根据具体情况选择性适配。
完成上述适配过程中,如果遇到问题,可以参考模型调试定位问题发生的代码位置。适配完成后,用户可参考模型保存与导出选择模型的保存导出方式,此功能默认支持,无需特殊适配。
详细的适配流程如 图 所示。

图1 迁移适配流程图
模型迁移
脚本迁移说明
脚本迁移操作的目的是将PyTorch的训练脚本迁移到昇腾AI处理器上,以支持模型在昇腾NPU上训练。
目前支持3种迁移方式:自动迁移(推荐)、工具迁移、手工迁移。推荐用户使用最简单的自动迁移方式。
- 自动迁移:在训练脚本中导入脚本转换库,然后拉起脚本执行训练。训练脚本在运行时,会自动将脚本中的CUDA接口替换为昇腾AI处理器支持的NPU接口。整体过程为边训练边转换。
- 工具迁移:使用迁移工具(pytorch_gpu2npu或PyTorch GPU2Ascend),自动将训练脚本中的CUDA接口替换为昇腾AI处理器支持的NPU接口,并生成迁移报告(脚本转换日志、不支持算子的列表、脚本修改记录)。训练时,运行转换后的脚本。整体过程为先转换脚本,再进行训练。
- 手工迁移:通过分析模型,对比GPU与NPU接口,手动对训练脚本进行修改,以支持在昇腾AI处理器上执行训练。迁移要点如下。
- 定义NPU为训练设备,将训练脚本中适配GPU的接口切换至适配NPU的接口。
- 多卡迁移需修改芯片间通信方式为昇腾支持的hccl。
自动迁移(推荐)
简介
自动迁移操作简单,且修改内容少,只需在训练脚本中导入库代码即可完成脚本迁移。
使用约束
说明
仅支持PyTorch 1.11.0版本及以上使用。
当前自动迁移暂不支持channel_last特性,建议用户使用contiguous代替。
若原脚本中使用的backend为nccl,在init_process_group初始化进程组后,backend已被自动迁移工具替换为hccl。如果后续代码逻辑包含backend是否为nccl的判断,例如assert backend in ['gloo', 'nccl']、if backend == 'nccl',请手动将字符串nccl改写为hccl。
由于自动迁移工具使用了Python的动态特性,但torch.jit.script不支持Python的动态语法,因此用户原训练脚本中包含torch.jit.script时使用自动迁移功能会产生冲突,目前自动迁移时会屏蔽torch.jit.script功能,若用户脚本中必须使用torch.jit.script功能,请使用工具迁移进行迁移。
使用方法
在训练脚本中导入库代码。
shellimport torch import torch_npu ..... from torch_npu.contrib import transfer_to_npu说明
- 仅PyTorch框架下需要导入from torch_npu.contrib import transfer_to_npu代码。
- 自动迁移工具与已适配的《套件与三方库支持清单》可能存在功能冲突,若发生冲突,请使用工具迁移进行迁移。
参考环境变量和脚本配置执行训练。如果训练正常进行,开始打印迭代日志,说明训练功能迁移成功。
参考模型保存与导出,如果成功保存权重,说明保存权重功能迁移成功。
手动迁移
简介
手工迁移需要用户对AI模型有迁移基础,了解GPU与NPU的接口设计的异同点以及各种迁移手段。手工迁移过程中,各个模型使用的迁移方法不完全相同,下文给出手工迁移的核心要点。
单卡迁移
导入NPU相关库。
pythonimport torch import torch_npu指定NPU作为训练设备。指定训练设备需修改模型训练脚本,有两种指定方式:
.to(device) 方式:定义好device后可通过 xx.to(device)的方式将模型或数据集等加载到GPU或NPU上,如model.to(device)。 该方式可以指定需要的训练资源,使用比较灵活。
迁移前:
pythondevice = torch.device('cuda:{}'.format(args.gpu))迁移后:
pythondevice = torch.device('npu:{}'.format(args.gpu))set_device
方式:调用set_device接口,指定训练设备。需注意该方式不会自动使用NPU,用户需要手动在想使用NPU的地方,添加xx.npu()代码,将模型数据集等加载到NPU上,如model.npu()。
迁移前:
pythontorch.cuda.set_device(args.gpu)迁移后:
pythontorch_npu.npu.set_device(args.gpu)
替换CUDA接口:将训练脚本中的CUDA接口替换为NPU接口,例如模型、损失函数、数据集等迁移到NPU上。常见替换接口请参见常见PyTorch迁移替换接口。更多接口请参见《API 参考》。
CUDA接口替换为NPU接口。
迁移前:
pythontorch.cuda.is_available()迁移后:
pythontorch_npu.npu.is_available()模型迁移。
迁移前:
pythonmodel.cuda(args.gpu)迁移后:
pythonmodel.npu(args.gpu)数据集迁移。
迁移前:
pythonimages = images.cuda(args.gpu, non_blocking=True) target = target.cuda(args.gpu, non_blocking=True)迁移后:
pythonimages = images.npu(args.gpu, non_blocking=True) target = target.npu(args.gpu, non_blocking=True)
多卡迁移(分布式训练迁移)
除单卡迁移包含的3个修改要点外,在分布式场景下,还需要切换通信方式,直接修改init_process_group的值。
修改前,GPU使用nccl方式:
dist.init_process_group(backend='nccl',init_method = "tcp://127.0.0.1:**", ...... ,rank = args.rank) # **为端口号,根据实际选择一个闲置端口填写修改后,NPU使用hccl方式:
dist.init_process_group(backend='hccl',init_method = "tcp://127.0.0.1:**", ...... ,rank = args.rank) # **为端口号,根据实际选择一个闲置端口填写工具迁移
工具迁移支持使用命令行、图形界面两种方式。
本节介绍命令行工具迁移方式,若用户想使用图形界面(MindStudio),可以参考《MindStudio IDE用户指南》中的“PyTorch GPU2Ascend”章节使用MindStudio中集成的PyTorch GPU2Ascend功能进行工具迁移。
使用约束
说明
若用户训练脚本中包含昇腾NPU平台不支持的amp_C模块,需要用户手动删除后再进行训练。
由于转换后的脚本与原始脚本平台不一致,迁移后的脚本在调试运行过程中可能会由于算子差异等原因而抛出异常,导致进程终止,该类异常需要用户根据异常信息进一步调试解决。
使用方法
使用命令行方式进行工具迁移的核心步骤如下:
环境准备。
安装开发套件包Ascend-cann-toolkit。具体操作请参考《CANN 软件安装指南》。
须安装如下依赖(以root用户安装为例,非root用户需加--user参数)。
shellpip3 install pandas #pandas版本号需大于或等于1.2.4 pip3 install libcst #Python语法树解析器,用于解析Python文件 pip3 install prettytable #将数据可视化为图表形式 pip3 install jedi #可选,用于跨文件解析,建议安装
进入迁移工具所在路径。
shellcd Ascend-cann-toolkit安装目录/ascend-toolkit/latest/tools/ms_fmk_transplt/进入分析迁移工具所在路径,执行脚本迁移任务。
shell./pytorch_gpu2npu.sh -i 原始脚本路径 -o 脚本迁移结果输出路径 -v 原始脚本框架版本 [-s] [-m] [distributed -t 目标模型变量名 -m 训练脚本的入口文件]distributed及其参数-m、-t在语句最后指定。
示例参考:
shell#单卡 ./pytorch_gpu2npu.sh -i /home/train/ -o /home/out -v 1.11.0 [-s] [-m] #分布式 ./pytorch_gpu2npu.sh -i /home/train/ -o /home/out -v 1.11.0 [-s] [-m] distributed -m /home/train/train.py [-t model]“[]”表示可选参数,实际使用可不用添加。
环境变量配置
在开始训练前,需要先配置训练相关环境变量,用于配置昇腾NPU上的PyTorch训练环境,一般使用shell脚本配置,具体配置步骤与示例如下:
- 配置环境变量shell脚本,示例如下。
# 配置CANN相关环境变量
CANN_INSTALL_PATH_CONF='/etc/Ascend/ascend_cann_install.info'
if [ -f $CANN_INSTALL_PATH_CONF ]; then
DEFAULT_CANN_INSTALL_PATH=$(cat $CANN_INSTALL_PATH_CONF | grep Install_Path | cut -d "=" -f 2)
else
DEFAULT_CANN_INSTALL_PATH="/usr/local/Ascend/"
fi
CANN_INSTALL_PATH=${1:-${DEFAULT_CANN_INSTALL_PATH}}
if [ -d ${CANN_INSTALL_PATH}/ascend-toolkit/latest ];then
source ${CANN_INSTALL_PATH}/ascend-toolkit/set_env.sh
else
source ${CANN_INSTALL_PATH}/nnae/set_env.sh
fi
# 导入依赖库
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/openblas/lib
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib/
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/lib64/
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/lib/
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/lib/aarch64_64-linux-gnu
# 配置自定义环境变量
export HCCL_WHITELIST_DISABLE=1 # 关闭HCCL通信白名单
# 日志信息配置
export ASCEND_SLOG_PRINT_TO_STDOUT=0 # 日志打屏, 可选
export ASCEND_GLOBAL_LOG_LEVEL=3 # 日志级别常用 1 INFO级别; 3 ERROR级别
export ASCEND_GLOBAL_EVENT_ENABLE=0 # 默认不使能event日志信息- 在拉起训练前,执行1配置的环境变量脚本。
source env.sh # env.sh为环境变量名称,用户需根据实际情况进行修改模型脚本与启动脚本配置
单机单卡场景
环境准备
- 请参考《Ascend Extension for PyTorch 配置与安装》手册,准备昇腾环境,包括硬件与OS,NPU驱动固件、CANN软件、PyTorch的安装。
- 根据实际需求准备模型环境,如conda、docker以及三方库依赖。
模型脚本配置
以常见的PyTorch模型,GPU训练为例:
通常模型源码支持GPU单机单卡训练,用户根据模型脚本迁移章节的指导,将模型源码映射至NPU,即可完成模型脚本配置。如果模型源码仅使用了CPU编程,不支持GPU单机单卡训练,用户可使用如下命令,将数据、模型放置NPU上训练:
import torch
import torch_npu
device = torch.device("npu")
# 将数据to npu
for data in dataloder:
if torch.npu.is_available():
data.to(device)
# 将模型to npu
model = Model()
if torch.npu.is_available():
model.to(device)
# 将损失函数to npu
loss_fn = nn.CrossEntropyLoss()
if torch.npu.is_available():
loss_fn=loss_fn.to(device)启动脚本配置
执行如下命令启动脚本拉起单机训练(以下参数为举例,用户可根据实际情况自行改动)。
python3 main.py --batch-size 128 \ # 训练批次大小,请尽量设置为处理器核数的倍数以更好的发挥性能
--data_path /home/data/resnet50/imagenet # 数据集路径
--lr 0.1 \ # 学习率
--epochs 90 \ # 训练迭代轮数
--arch resnet50 \ # 模型架构
--world-size 1 \
--rank 0 \
--workers 40 \ # 加载数据进程数
--momentum 0.9 \ # 动量
--weight-decay 1e-4 \ # 权重衰减
--gpu 0 # device号, 这里参数名称仍为gpu, 但迁移完成后实际训练设备已在代码中定义为npu单机多卡场景
环境准备
- 请参考《Ascend Extension for PyTorch 配置与安装》手册,准备昇腾环境,包括硬件与OS,NPU驱动固件、CANN软件、PyTorch的安装。
- 根据实际需求准备模型环境,如conda、docker以及三方库依赖。
模型脚本配置
本节以适配样例(DDP场景)章节的代码为样例,介绍将单机单卡训练脚本修改为单机多卡训练脚本的核心步骤。
在主函数中添加如下代码。
在shell脚本中循环传入local_rank变量作为指定的device。
说明
此操作以shell脚本方式修改为例,用户可参考拉起多卡训练脚本示例用其他方式进行修改。
shelllocal_rank = int(os.environ["LOCAL_RANK"])用local_rank自动获取device号。
shelldevice = torch.device('npu', local_rank)初始化,将通信方式设置为hccl。
shelltorch.distributed.init_process_group(backend="hccl",rank=local_rank)
在获取训练数据集后,设置train_sampler。
shelltrain_sampler = torch.utils.data.distributed.DistributedSampler(train_data)定义模型后,开启DDP模式。
shellmodel = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)将数据加载器train_dataloader与train_sampler相结合。
shelltrain_dataloader = DataLoader(dataset = train_data, batch_size=batch_size, sampler = train_sampler)
启动脚本配置
有5种方式脚本启动方式可拉起多卡训练:
- shell脚本方式(推荐)
- mp.spawn 方式
- Python 方式
- torchrun 方式:仅在PyTorch 1.11.0及以上版本支持使用。
- torch_npu_run 方式(集群场景推荐):此方式是torchrun在大集群场景的改进版,提升集群建链性能,仅在PyTorch 1.11.0版本支持使用。
附录拉起单机八卡训练中,以一个简单模型脚本为样例,展示了每种拉起方式脚本代码的修改方法以及各种拉起方式的适配方法,用户可以参考学习。
多机多卡场景
环境准备
准备集群环境时,集群中的各个单机需要按照环境准备部署好环境,确保单机可以正常运行。
此外还需要进行按照如下操作进行集群配置。
说明
- 集合通信仅支持1/2/4/8P粒度的分配。
- 以下操作除模型修改外,只需配置执行一次。
准备组网,以两台8卡服务器组网为例。
通过交换机或光口直连的方式完成计算设备组网搭建。
配置device IP。
- 在AI Server0上配置device IP,以下IP为示例。
shellhccn_tool -i 0 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 1 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 2 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 3 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 4 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 5 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 6 -ip -s address 192.***.***.001 netmask 255.255.255.0 hccn_tool -i 7 -ip -s address 192.***.***.001 netmask 255.255.255.0- 在AI Server1上配置device IP,以下IP为示例。
shellhccn_tool -i 0 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 1 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 2 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 3 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 4 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 5 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 6 -ip -s address 192.***.***.002 netmask 255.255.255.0 hccn_tool -i 7 -ip -s address 192.***.***.002 netmask 255.255.255.0说明
配置device IP需遵守以下规则:
- 针对Atlas 训练系列产品,AI Server中的第0/4、1/5、2/6、3/7号device需处于同一网段,第0/1/2/3号device在不同网段,第4/5/6/7号device在不同网段;对于集群场景,各AI Server对应的位置的device需处于同一网段,AI Server0和AI Server1的0号网卡需处于同一网段、1号网卡需要在同一网段。
- 针对Atlas A2 训练系列产品,多台节点的NPU在同一网段即可。
- 每个IP都不能冲突,相同网段下的IP需在最后8位做区分。
- 使用hccn_tool 确保两机器的卡间连通性,从device0 - devcie7 测试8次,确保两台机器间所有卡都连通。
shellhccn_tool -i 0 -netdetect -s address xx.xx.xx.xx hccn_tool -i 0 -net_health -g #-s address:xx.xx.xx.xx是另外一台机器的device i的IP #-i:device序号使用hccn_tool工具验证device IP是否配置正确。
- 查询每个device的ip:
hccn_tool -i 0 -ip -g- 打印查询结果:
ipaddr:192.***.***.001 netmask:255.255.255.0如果返回success则表示已经连通。
关闭防火墙。
Ubuntu系统防火墙关闭命令。
ufw disableRedhat或CentOS 7系统防火墙关闭命令。
systemctl stop firewalld
确认交换机状态正常。
执行以下命令,返回值不为空则正常。
for i in {0..7}; do hccn_tool -i $i -lldp -g; done修改模型。可参考模型脚本配置,将模型脚本上传至AI Server0和AI Server1任意路径下。
拉起多机多卡训练。需注意以下要点:
在所有脚本统一主节点的MASTER_PORT和MASTER_ADDR。
配置相应的rank与world_size。
查看host日志。
所有host日志统一保存在~/ascend/log路径下,用户可以在该路径下查看每个host的device日志。
- 由于Master节点允许处理的并发建链数受Linux内核参数“somaxconn”与“tcp_max_syn_backlog”的限制,所以,针对大规模集群组网,若“somaxconn”与“tcp_max_syn_backlog”取值较小会导致部分客户端概率性提前异常退出,导致集群初始化失败。
大规模集群组网场景下,建议用户根据集群数量适当调整“somaxconn”与“tcp_max_syn_backlog”参数的值,例如:
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.tcp_max_syn_backlog=65535
sysctl -w net.ipv4.ip_local_reserved_ports=60000-60015说明
如果用户在物理机场景训练,则需要在物理机上配置以上命令;若是在容器场景训练,则需要在容器中配置以上命令。
模型脚本配置
本节以适配样例(DDP场景)章节的代码为样例,为用户介绍将单卡训练脚本修改为多卡训练脚本的核心步骤。
在主函数中添加如下代码。
在shell脚本中循环传入local_rank变量作为指定的device。
说明
此操作以shell脚本方式修改为例,用户可参考拉起多卡训练脚本示例用其他方式进行修改。
local_rank = int(os.environ["LOCAL_RANK"])用local_rank自动获取device号。
device = torch.device('npu', local_rank)初始化,将通信方式设置为hccl。
shelltorch.distributed.init_process_group(backend="hccl",rank=local_rank)
在获取训练数据集后,设置train_sampler。
shelltrain_sampler = torch.utils.data.distributed.DistributedSampler(train_data)定义模型后,开启DDP模式。
shellmodel = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)将数据加载器train_dataloader与train_sampler相结合。
shelltrain_dataloader = DataLoader(dataset = train_data, batch_size=batch_size, sampler = train_sampler)
启动脚本配置
有4种脚本启动方式可拉起多卡训练:
- shell脚本方式(推荐)
- Python方式
- torchrun方式:仅在PyTorch 1.11.0及以上版本支持使用。
- torch_npu_run方式(集群场景推荐):此方式是torchrun在大集群场景的改进版,提升集群建链性能,仅在PyTorch 1.11.0版本支持使用。
附录拉起双机16卡训练中,以一个简单模型脚本为样例,展示了每种拉起方式脚本代码的修改方法以及各种拉起方式的适配方法,用户可以参考学习。
Torch-NPU 迁移实例
1. 简单模型迁移训练
本节提供了一个简单的模型迁移样例,采用了最简单的自动迁移方法,帮助用户快速体验GPU模型脚本迁移到昇腾NPU上的流程,将在GPU上训练CNN模型识别手写数字的脚本代码进行修改,使其可以迁移到昇腾NPU上进行训练。
新建脚本train.py,写入以下原GPU脚本代码。
python# 引入模块 import time import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader import torchvision # 初始化运行device device = torch.device('cuda:0') # 定义模型网络 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.net = nn.Sequential( # 卷积层 nn.Conv2d(in_channels=1, out_channels=16, kernel_size=(3, 3), stride=(1, 1), padding=1), # 池化层 nn.MaxPool2d(kernel_size=2), # 卷积层 nn.Conv2d(16, 32, 3, 1, 1), # 池化层 nn.MaxPool2d(2), # 将多维输入一维化 nn.Flatten(), nn.Linear(32*7*7, 16), # 激活函数 nn.ReLU(), nn.Linear(16, 10) ) def forward(self, x): return self.net(x) # 下载数据集 train_data = torchvision.datasets.MNIST( root='mnist', download=True, train=True, transform=torchvision.transforms.ToTensor() ) # 定义训练相关参数 batch_size = 64 model = CNN().to(device) # 定义模型 train_dataloader = DataLoader(train_data, batch_size=batch_size) # 定义DataLoader loss_func = nn.CrossEntropyLoss().to(device) # 定义损失函数 optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 定义优化器 epochs = 10 # 设置循环次数 # 设置循环 for epoch in range(epochs): for imgs, labels in train_dataloader: start_time = time.time() # 记录训练开始时间 imgs = imgs.to(device) # 把img数据放到指定NPU上 labels = labels.to(device) # 把label数据放到指定NPU上 outputs = model(imgs) # 前向计算 loss = loss_func(outputs, labels) # 损失函数计算 optimizer.zero_grad() loss.backward() # 损失函数反向计算 optimizer.step() # 更新优化器 # 定义保存模型 torch.save({ 'epoch': 10, 'arch': CNN, 'state_dict': model.state_dict(), 'optimizer' : optimizer.state_dict(), },'checkpoint.pth.tar')在train.py中添加以下加粗部分库代码。
- 若用户使用Atlas 训练系列产品,由于其架构特性限制,用户在训练时需要开启混合精度(AMP),可以提升模型的性能。具体介绍可参见《PyTorch 训练模型迁移调优指南》中的“(可选)混合精度适配”章节。
- 若用户使用Atlas A2 训练系列产品,则可以选择不开启混合精度(AMP)。
pythonimport time import torch ...... import torch_npu from torch_npu.npu import amp # 导入AMP模块 from torch_npu.contrib import transfer_to_npu # 使能自动迁移若未使能自动迁移,用户可参考《PyTorch 训练模型迁移调优指南》中的“手工迁移”章节进行相关操作。
使能AMP混合精度计算。若用户使用Atlas A2 训练系列产品,则可以选择跳过此步骤。在模型、优化器定义之后,定义AMP功能中的GradScaler。
python...... loss_func = nn.CrossEntropyLoss().to(device) # 定义损失函数 optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 定义优化器 scaler = amp.GradScaler() # 在模型、优化器定义之后,定义GradScaler epochs = 10这一部分我们在训练代码中添加AMP功能相关的代码开启AMP。
python...... for i in range(epochs): for imgs, labels in train_dataloader: imgs = imgs.to(device) labels = labels.to(device) with amp.autocast(): outputs = model(imgs) # 前向计算 loss = loss_func(outputs, labels) # 损失函数计算 optimizer.zero_grad() # 进行反向传播前后的loss缩放、参数更新 scaler.scale(loss).backward() # loss缩放并反向转播 scaler.step(optimizer) # 更新参数(自动unscaling) scaler.update() # 基于动态Loss Scale更新loss_scaling系数执行命令启动训练脚本(命令脚本名称可根据实际修改)。
shellpython3 train.py训练结束后生成如下图权重文件,则说明迁移训练成功。
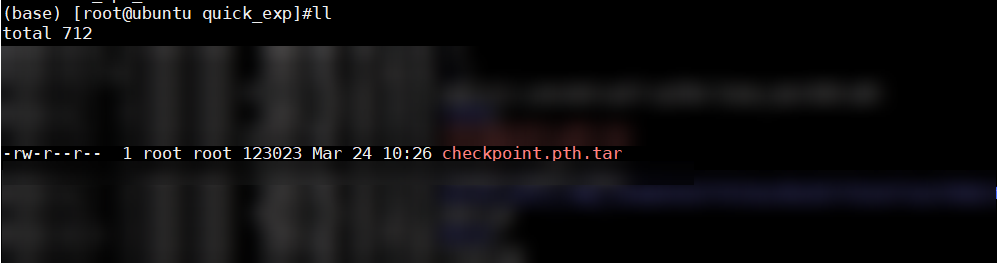
2. 拉起多卡训练脚本示例
构建模型脚
# 导入依赖和库
import torch
from torch import nn
import torch_npu
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import time
import torch.multiprocessing as mp
import os
torch.manual_seed(0)
# 下载训练数据
training_data = datasets.FashionMNIST(
root="./data",
train=True,
download=True,
transform=ToTensor(),
)
# 下载测试数据
test_data = datasets.FashionMNIST(
root="./data",
train=False,
download=True,
transform=ToTensor(),
)
# 构建模型
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")获取分布式超参数
在模型脚本中,构建主函数main,在其中获取分布式训练所需的超参数。
shell脚本/torchrun/torch_npu_run方式
shelldef main(world_size: int, batch_size = 64, total_epochs = 5,): # 用户可自行设置 ngpus_per_node = world_size main_worker(args.gpu, ngpus_per_node, args)mp.spawn方式
shelldef main(world_size: int, batch_size = 64, total_epochs = 5,): # 用户可自行设置 ngpus_per_node = world_size mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args)) # mp.spawn方式启动Python方式
shelldef main(world_size: int, batch_size, args): # 使用Python拉起命令中设置的超参数 ngpus_per_node = world_size args.gpu = args.local_rank # 任务拉起后,local_rank自动获得device号 main_worker(args.gpu, ngpus_per_node, args)
设置地址和端口号
在模型脚本中设置地址与端口号,用于拉起分布式训练。由于昇腾AI处理器初始化进程组时initmethod只支持env:// (即环境变量初始化方式),所以在初始化前需要根据实际情况配置MASTER_ADDR、MASTER_PORT等参数。
shell脚本/mp.spawn/torchrun方式的配置代码相同,如下所示:
shelldef ddp_setup(rank, world_size): """ Args: rank: Unique identifier of each process world_size: Total number of processes """ os.environ["MASTER_ADDR"] = "localhost" # 用户需根据自己实际情况设置 os.environ["MASTER_PORT"] = "***" # 用户需根据自己实际情况设置 dist.init_process_group(backend="hccl", rank=rank, world_size=world_size)torch_npu_run方式,使用时需切换通信方式,修改init_process_group接口的参数。
修改前:init_method使用tcp方式
shelldist.init_process_group(..., init_method="tcp://xx:**", ......, ) # xx为rank0节点通信ip,**为端口号,根据实际选择一个闲置端口填写修改后:init_method使用parallel方式
dist.init_process_group(..., init_method="parallel://xx:**", ......, ) # xx为rank0节点通信ip,**为端口号,根据实际选择一个闲置端口填写Python方式需要把配置参数的命令放到拉起训练中。脚本中代码如下所示:
shelldef ddp_setup(rank, world_size): """ Args: rank: Unique identifier of each process world_size: Total number of processes """ dist.init_process_group(backend="hccl", rank=rank, world_size=world_size)
添加分布式逻辑
不同的拉起训练方式下,device号的获取方式不同:
- shell 脚本
/torchrun/torch_npu_run方式:在shell脚本中循环传入local_rank变量作为指定的device。 - mp.spawn方式:mp.spawn多进程拉起main_worker后,第一个参数GPU自动获得device号(0 ~ ngpus_per_node - 1)。
- Python方式:任务拉起后,local_rank自动获得device号。
用户需根据自己选择的方式对代码做不同的修改。下面是修改代码示例:
shell脚本 /torchrun/torch_npu_run方式
pythondef main_worker(gpu, ngpus_per_node, args): start_epoch = 0 end_epoch = 5 args.gpu = int(os.environ['LOCAL_RANK']) # 在shell脚本中循环传入local_rank变量作为指定的device ddp_setup(args.gpu, args.world_size) torch_npu.npu.set_device(args.gpu) total_batch_size = args.batch_size total_workers = ngpus_per_node batch_size = int(total_batch_size / ngpus_per_node) workers = int((total_workers + ngpus_per_node - 1) / ngpus_per_node) model = NeuralNetwork() device = torch.device("npu") train_sampler = torch.utils.data.distributed.DistributedSampler(training_data) test_sampler = torch.utils.data.distributed.DistributedSampler(test_data) train_loader = torch.utils.data.DataLoader( training_data, batch_size=batch_size, shuffle=(train_sampler is None), num_workers=workers, pin_memory=False, sampler=train_sampler, drop_last=True) val_loader = torch.utils.data.DataLoader( test_data, batch_size=batch_size, shuffle=(test_sampler is None), num_workers=workers, pin_memory=False, sampler=test_sampler, drop_last=True) loc = 'npu:{}'.format(args.gpu) model = model.to(loc) criterion = nn.CrossEntropyLoss().to(loc) optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu]) for epoch in range(start_epoch, end_epoch): print("curr epoch: ", epoch) train_sampler.set_epoch(epoch) train(train_loader, model, criterion, optimizer, epoch, args.gpu)
def train(train_loader, model, criterion, optimizer, epoch, gpu):
size = len(train_loader.dataset)
model.train()
end = time.time()
for i, (images, target) in enumerate(train_loader):
# measure data loading time
loc = 'npu:{}'.format(gpu)
target = target.to(torch.int32)
images, target = images.to(loc, non_blocking=False), target.to(loc, non_blocking=False)
# compute output
output = model(images)
loss = criterion(output, target) # compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
end = time.time()
if i % 100 == 0:
loss, current = loss.item(), i * len(target)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
```python
def main_worker(gpu, ngpus_per_node, args):
start_epoch = 0
end_epoch = 5
ddp_setup(gpu, args.world_size)
torch_npu.npu.set_device(gpu)
total_batch_size = args.batch_size
total_workers = ngpus_per_node
batch_size = int(total_batch_size / ngpus_per_node)
workers = int((total_workers + ngpus_per_node - 1) / ngpus_per_node)
model = NeuralNetwork()
device = torch.device("npu")
train_sampler = torch.utils.data.distributed.DistributedSampler(training_data)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_data)
train_loader = torch.utils.data.DataLoader(
training_data, batch_size=batch_size, shuffle=(train_sampler is None),
num_workers=workers, pin_memory=False, sampler=train_sampler, drop_last=True)
val_loader = torch.utils.data.DataLoader(
test_data, batch_size=batch_size, shuffle=(test_sampler is None),
num_workers=workers, pin_memory=False, sampler=test_sampler, drop_last=True)
loc = 'npu:{}'.format(gpu)
model = model.to(loc)
criterion = nn.CrossEntropyLoss().to(loc)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
for epoch in range(start_epoch, end_epoch):
print("curr epoch: ", epoch)
train_sampler.set_epoch(epoch)
train(train_loader, model, criterion, optimizer, epoch, gpu)
...... # train函数代码同shell脚本方式Python方式
shelldef main_worker(gpu, ngpus_per_node, args): start_epoch = 0 end_epoch = 5 args.gpu = args.local_rank # 任务拉起后,local_rank自动获得device号 ddp_setup(args.gpu, args.world_size) ...... # 其余代码同shell脚本方式
配置传参逻辑
在模型脚本中,根据拉起方式不同,需要传入不同的参数,传参配置逻辑如下(此处使用argparse逻辑):
shell脚本/torchrun/torch_npu_run方式
pythonif __name__ == "__main__": import argparse parser = argparse.ArgumentParser(description='simple distributed training job') parser.add_argument('--batch_size', default=512, type=int, help='Input batch size on each device (default: 32)') parser.add_argument('--gpu', default=None, type=int, help='GPU id to use.') args = parser.parse_args() world_size = torch.npu.device_count() args.world_size = world_size main(args.world_size, args.batch_size)mp.spawn方式
pythonif __name__ == "__main__": import argparse parser = argparse.ArgumentParser(description='simple distributed training job') parser.add_argument('--batch_size', default=512, type=int, help='Input batch size on each device (default: 32)') args = parser.parse_args() world_size = torch.npu.device_count() args.world_size = world_size main(args.world_size, args.batch_size)Python方式
pythonif __name__ == "__main__": import argparse parser = argparse.ArgumentParser(description='simple distributed training job') parser.add_argument('--batch_size', default=512, type=int, help='Input batch size on each device (default: 32)') parser.add_argument('--gpu', default=None, type=int, help='GPU id to use.') parser.add_argument("--local_rank", default=-1, type=int) # local_rank用于自动获取device号。使用mp.spawn方式与shell方式启动时需删除此项 args = parser.parse_args() world_size = torch.npu.device_count() args.world_size = world_size main(args.world_size, args.batch_size, args) # 需将Python拉起命令中设置的参数传入main函数
拉起单机八卡训练
我们给出了每种方式的拉起命令示例,用户可根据实际情况自行更改。
shell脚本方式
shellexport HCCL_WHITELIST_DISABLE=1 RANK_ID_START=0 WORLD_SIZE=8 for((RANK_ID=$RANK_ID_START;RANK_ID<$((WORLD_SIZE+RANK_ID_START));RANK_ID++)); do echo "Device ID: $RANK_ID" export LOCAL_RANK=$RANK_ID python3 ddp_test_shell.py & done waitmp.spawn方式
shellexport HCCL_WHITELIST_DISABLE=1 python3 ddp_test_spwn.pyPython方式
# master_addr和master_port参数需用户根据实际情况设置 export HCCL_WHITELIST_DISABLE=1 python3 -m torch.distributed.launch --nproc_per_node 8 --master_addr localhost --master_port *** ddp_test.pytorchrun方式
shellexport HCCL_WHITELIST_DISABLE=1 torchrun --standalone --nnodes=1 --nproc_per_node=8 ddp_test_shell.pytorch_npu_run方式
shellexport HCCL_WHITELIST_DISABLE=1 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR \ --master_port=$MASTER_PORT --nnodes=8 --nproc_per_node=8 ddp_test_shell.py
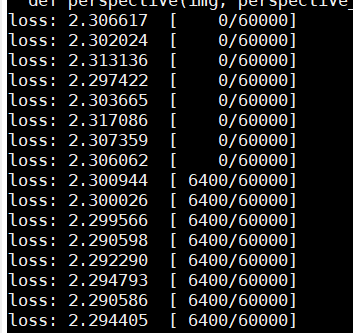
当屏幕打印/定向日志中出现模型加载、训练等正常运行日志时,说明拉起多卡训练成功,如图所示。
拉起双机16卡训练
启动命令需要在集群每台机器分别执行:
shell脚本方式
shell# 第一台机器 RANK_ID_START=0 NPU_PER_NODE=8 for((RANK_ID=$RANK_ID_START;RANK_ID<$((NPU_PER_NODE+RANK_ID_START));RANK_ID++)); do echo "Device ID: $RANK_ID" export LOCAL_RANK=$RANK_ID python3 ddp_test_shell.py & done wait # 第二台机器 RANK_ID_START=8 NPU_PER_NODE=8 for((RANK_ID=$RANK_ID_START;RANK_ID<$((NPU_PER_NODE+RANK_ID_START));RANK_ID++)); do echo "Device ID: $RANK_ID" export LOCAL_RANK=$RANK_ID python3 ddp_test_shell.py & done waitPython方式
shell# 第一台机器 # master_addr和master_port参数需用户根据实际情况设置 python3 -m torch.distributed.launch --nnodes=2 --nproc_per_node 8 --node_rank 0 --master_addr $master_addr --master_port $master_port ddp_test.py # 第二台机器 python3 -m torch.distributed.launch --nnodes=2 --nproc_per_node 8 --node_rank 1 --master_addr $master_addr --master_port $master_port ddp_test.pytorchrun方式
shell# 第一台机器 torchrun --nnodes=2 --nproc_per_node=8 --node_rank 0 ddp_test_shell.py # 第二台机器 torchrun --nnodes=2 --nproc_per_node=8 --node_rank 1 ddp_test_shell.pytorch_npu_run方式
shell# 第一台机器 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR \ --master_port=$MASTER_PORT --nnodes=2 --node_rank 0 --nproc_per_node=8 ddp_test_shell.py # 第二台机器 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR \ --master_port=$MASTER_PORT --nnodes=2 --node_rank 1 --nproc_per_node=8 ddp_test_shell.py
当屏幕打印/定向日志中出现模型加载、训练等正常运行日志时,说明拉起双机训练成功。